はじめに
最近、IoTLTやその派生のVUILTに参加してものづくりを学んでいたら、自分にもできそうな気がしてきたので、最近買ったGoogle Homeで何かできないかと考えてみました。音声のみで成り立つ何か・・・ちょうど自分が勉強しようと思っていた、かるた(百人一首)なら音だけで何か役立つものを作れるのではないかと思い、今回の題材に取り組んでみることにしました。
当初、想定した基本コンセプトは以下。
・初心者向け
・百首をランダムに読み上げてくれる
・決まり字を教えてくれる
・作者や歌の意味を教えてくれる
ネットの情報に頼りながら、なんとか基本コンセプトをほぼ満たすものができたので、自分用のメモとこれから似たようなプログラミングを始める人の参考になればと思いブログに書き留めます。
システム概要
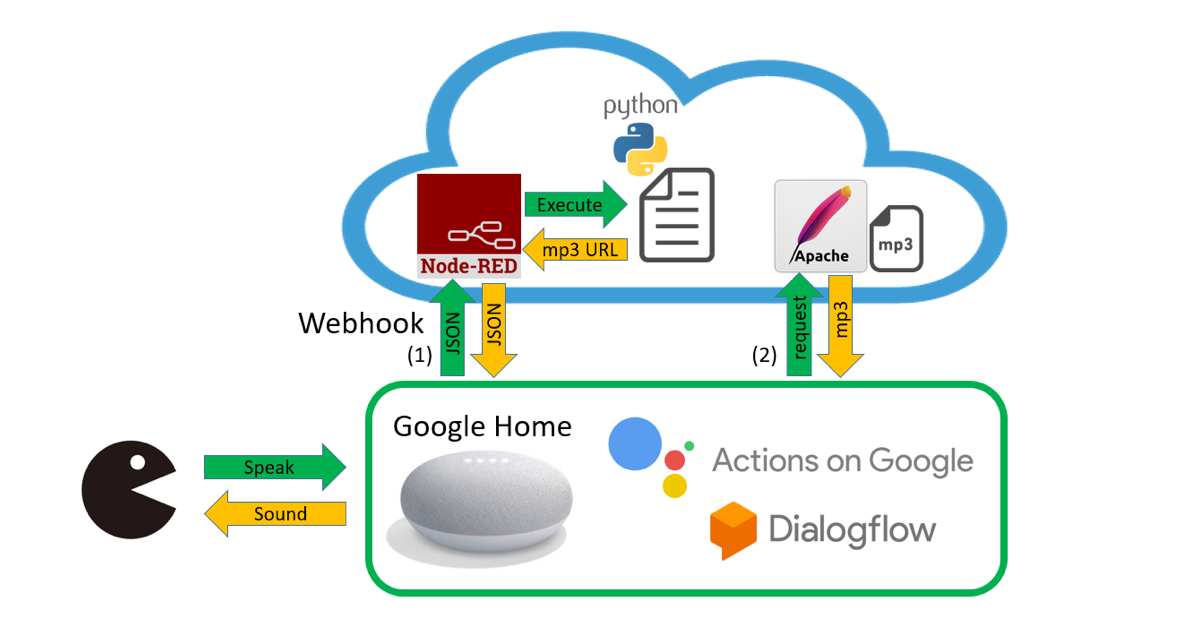
下図が「かるた読み」のシステム全体図。「かるた読みにつないで」でアプリが起動し、「始め」で序歌を読み、「次」でランダムに一首読み、作者と決まり字を教えてくれ、「終わり」で終了します。
Google Home用の会話インターフェイスをブラウザ上で構築できる仕組みが、「Actions on Google」と「Dialogflow」。これらはGoogleアカウントとGoogle Homeがあれば無料で使えます。
図中の雲の絵の部分はクラウドサーバで実現しています。今やクラウドサーバも無料のものがありますので、気軽に試すことができます。
DialogflowのWebhook機能を使ってクラウドサーバへのアクセスをしています。Webhookでの送受信はJSON(JavaScript Object Notation)形式のデータでやり取りされます。当初はここでMP3音声データもダウンロードしようと思っていましたが、やり方がわからなかったので、SSML(Speech Synthesis Markup Language)形式でMP3ファイルのURLを送り返すようにしました。
Google Homeは受け取ったURLにアクセスし、クラウド上で稼働しているApache(Webサーバプログラム)からMP3ファイルを受け取り、音声を再生します。
【実行例】
Actions on GoogleとDialogflow
新しいプロジェクトを作成します。
https://console.actions.google.com/
「Add/import project」を押す。
Project nameとCountry/regionを設定して「Create Project」ボタンを押す。
カテゴリを選択するか「SKIP」ボタンで次へ進む。
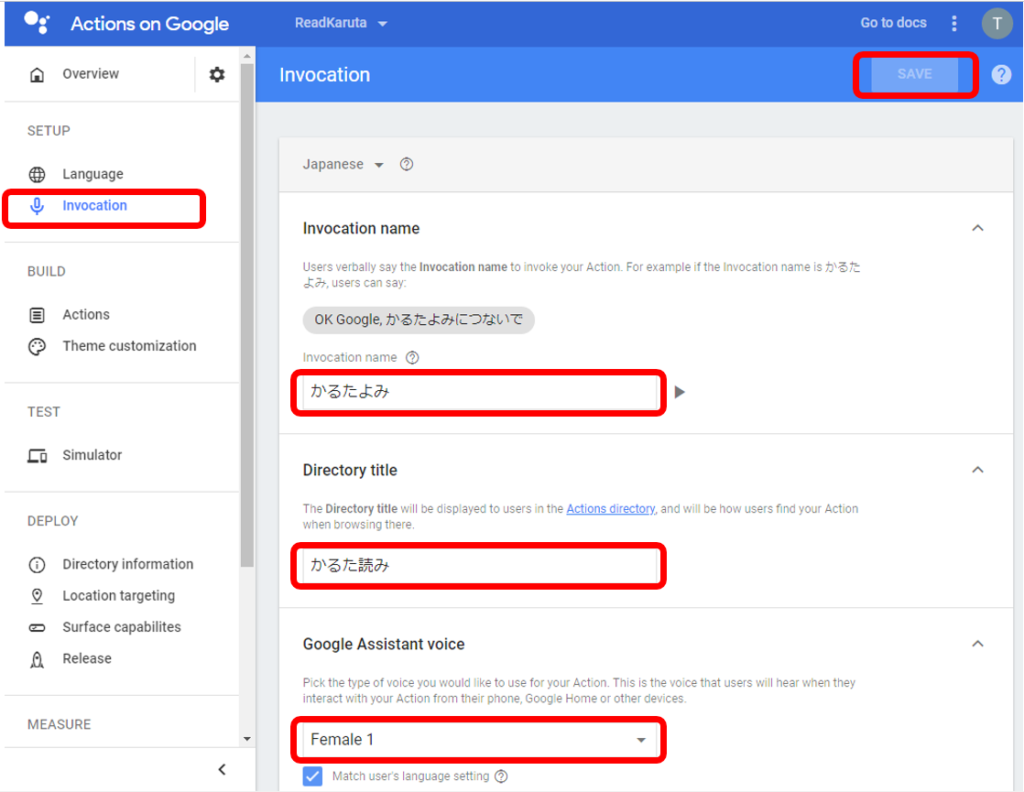
「Invocation」から起動ワードやタイトルを入れ「SAVE」を押す。
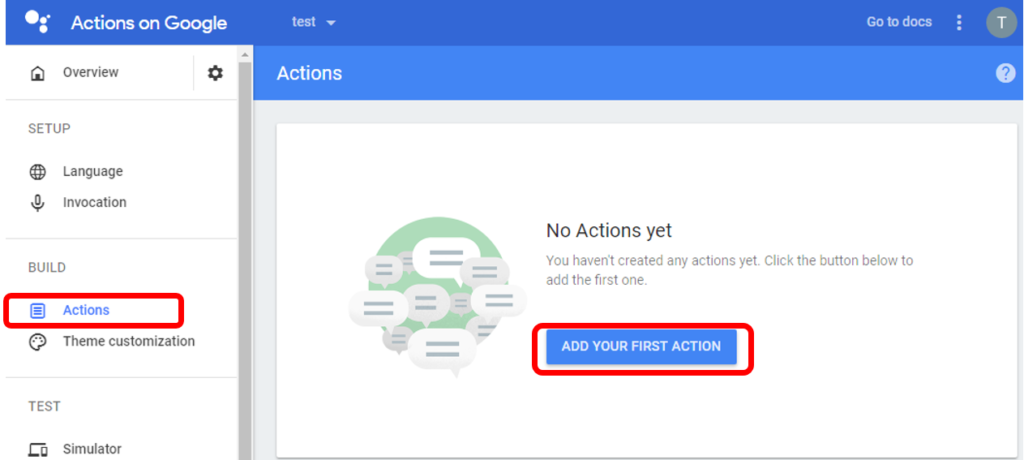
「Actions」から「ADD YOUR FIRST ACTION」を押します。
「Custom Intent」「BUILD」を押す。言語はJapaneseを選択。
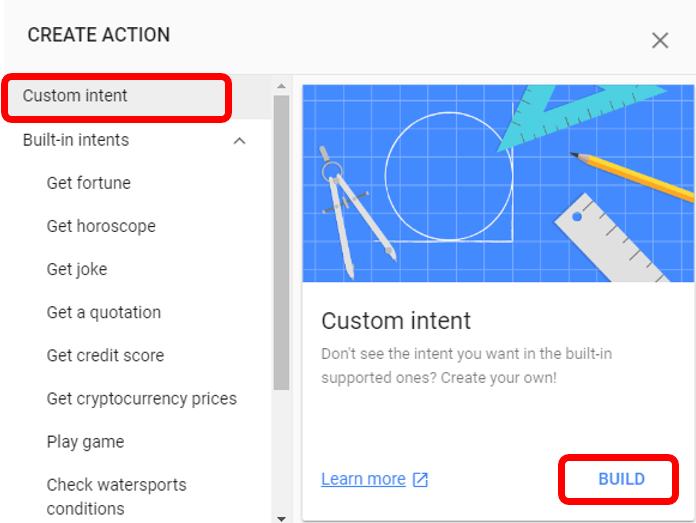
DialogflowからDefault Welcome Intentを編集します。アプリ起動時に話す内容をText responseに書き込みます。以降、修正を加えたら「SAVE」を押します。
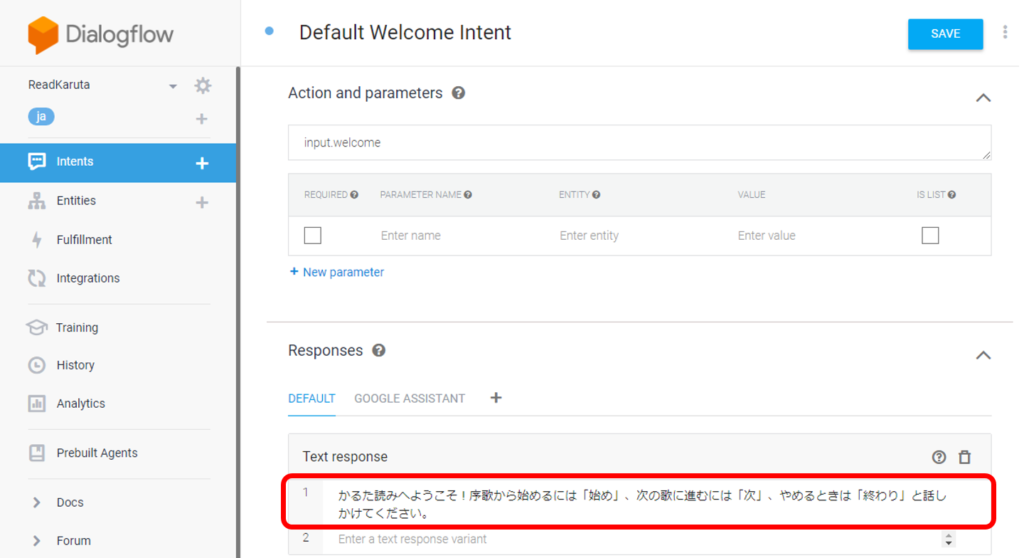
Intents→CREATE INTENTから、序歌を読むSTARTアクションを追加します。STARTアクションを実行するフレーズをTraining phrasesに記入し、クラウドサーバプログラムに渡す値をAction and parametersに定義します。ここでは、actionというパラメータに値initを設定しています。
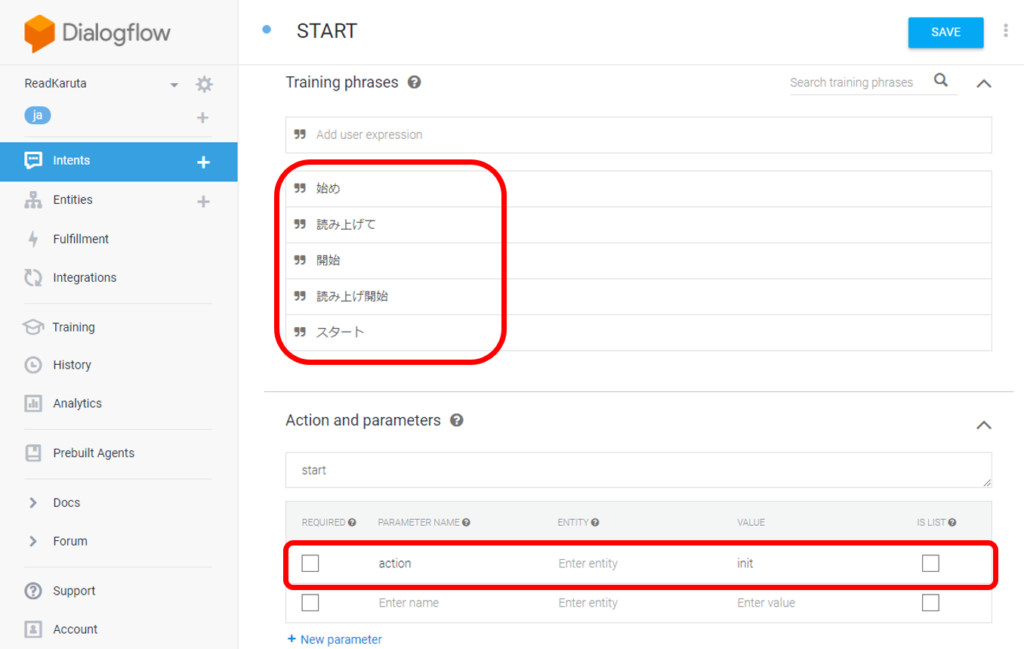
クラウドサーバプログラムを呼び出すため、下の方にあるFulfillmentのEnable webhook call for this intentをONにします。
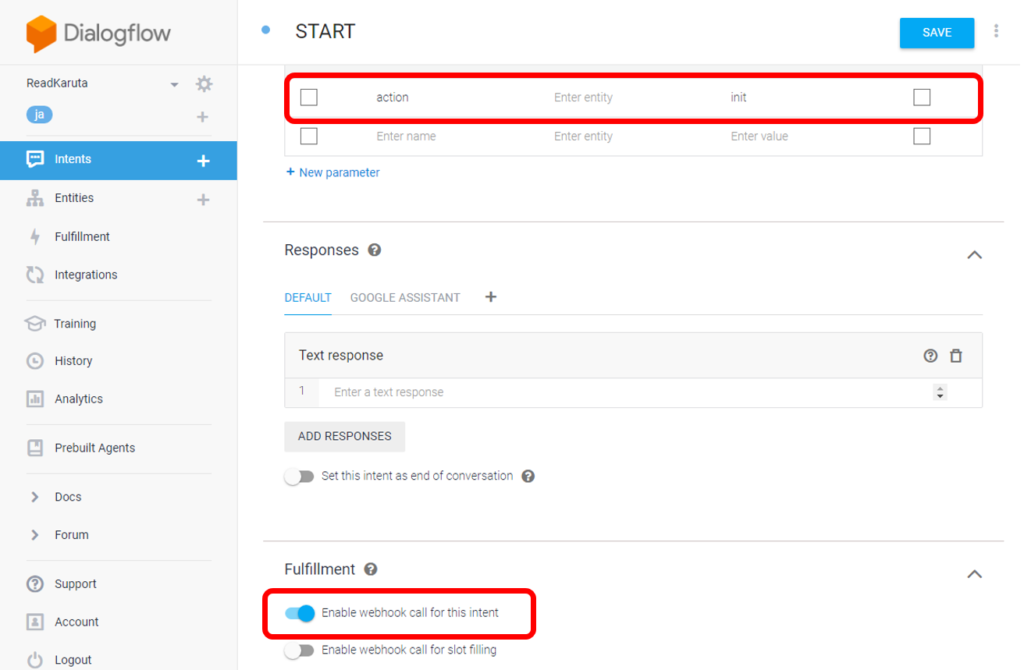
同様にNEXTアクションを追加。actionパラメータにはnextを設定。ここでもFulfillmentのEnable webhook call for this intentをONにします。
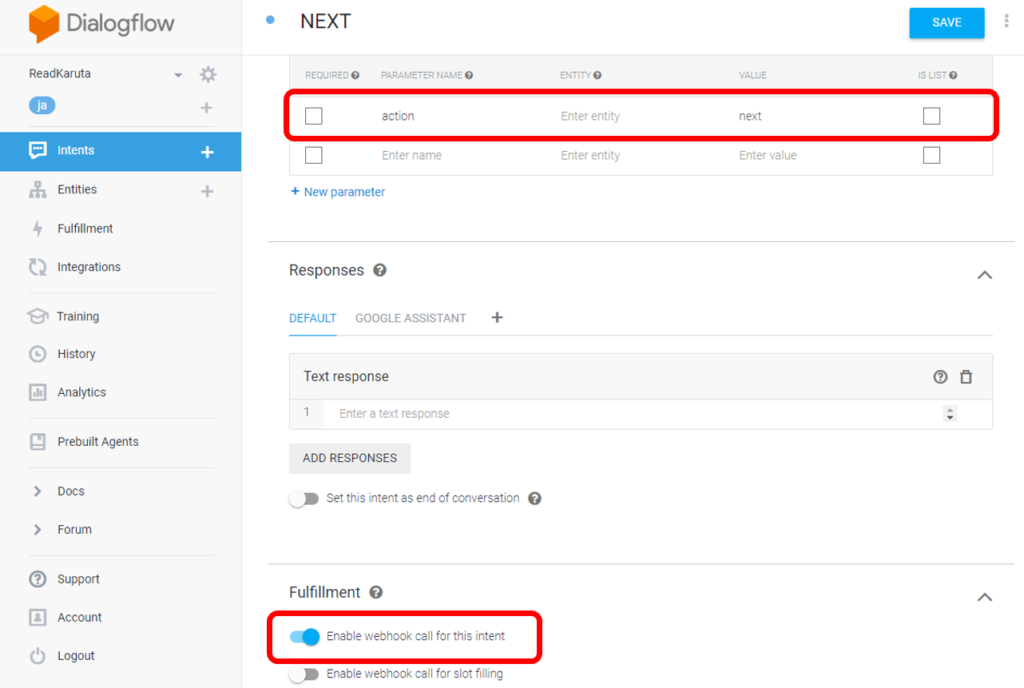
終了するためのENDアクションを追加します。Text responseに終了時に話す内容を記入し、Set this intent as end of conversationをONにします。
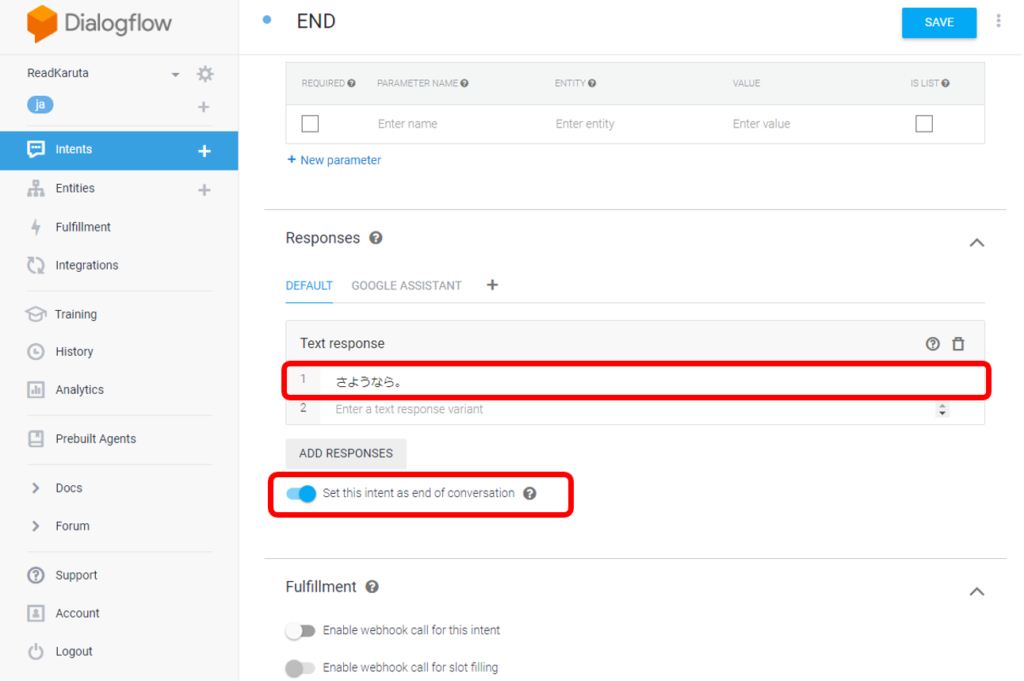
これで、Intentsは以下のようになります。
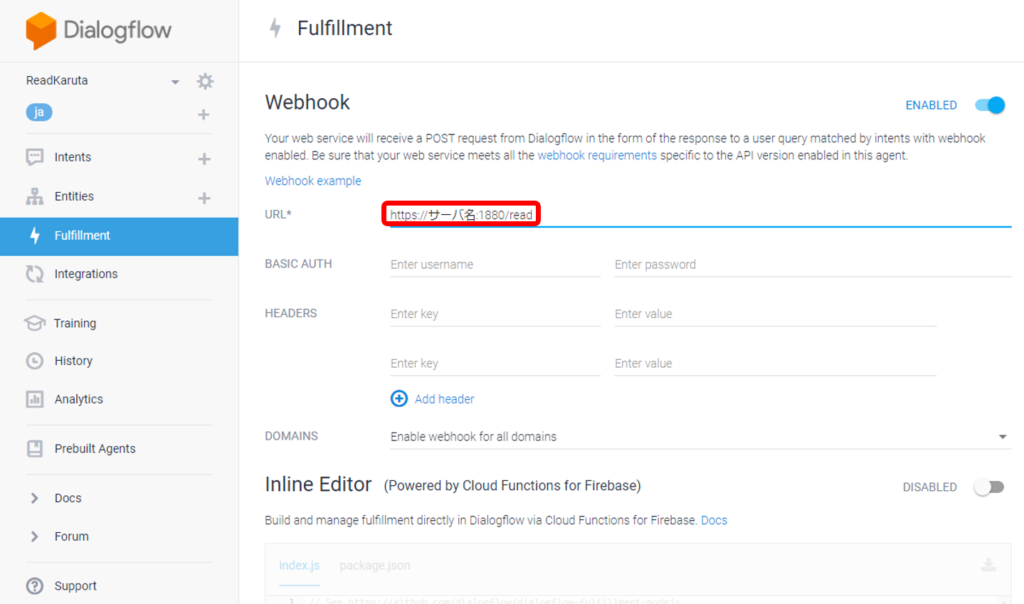
次にFulfillmentの設定をします。URLに”クラウドサーバのURL:ポート番号/リクエスト名”を入れます。クラウドサーバでNode-REDを使用する場合、デフォルトのポート番号は1880です。本アプリではリクエスト名をreadとしました。
なお、Entitiesはユーザから入力として受け付ける単語を定義するものですが、今回の機能の実現には不要だったので何も設定していません。
クラウドサーバでの処理
前述のWebhookから呼び出されるサーバ側の処理について説明していきます。クラウドサーバを立ち上げて使えるようにするまでの方法は、各クラウドサービスによって異なるため、ここでは省略します。
WebhookでGoogle HomeからHTTP POSTでJSONデータが送られてきます。これを処理するのにNode-REDを使用します。
「Node-RED最高!」とIoTLTで聞いていて今回初めて使ってみました。簡単にサーバ側の通信部分を構築できて、機能部分のコーディングに集中できるので確かに良いです。
とはいえ、Pythonプログラムとのインターフェイスなどハマった部分もあるので、回避方法についても説明します。(すべてJavaScriptで書いていれば、問題にならなかったと思います。)
Node-REDは、GUI(ブラウザ)から直感的な方法でNode.jsによるWeb通信を実現する環境を提供してくれます。
Node-RED User Group Japanのページの「インストール」や「起動」に説明があります。
Node-REDが起動しているクラウドサーバ上で、ブラウザから https://localhost:1880/ にアクセスすると、次のようなページが立ち上がります。(下図はフロー構築済み)
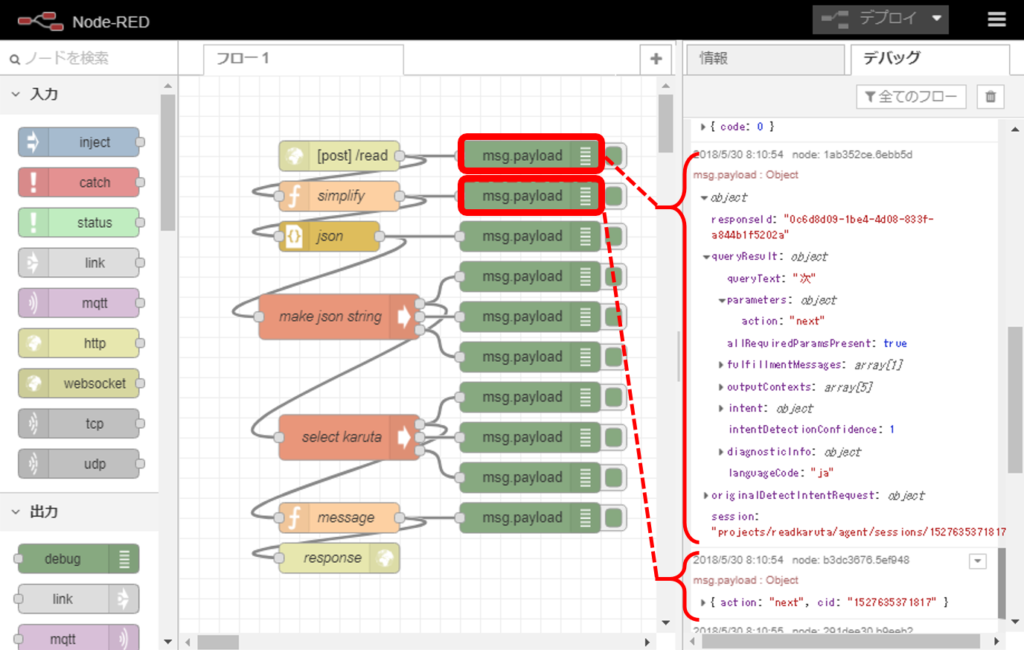
左側にあるノードを中央のフロー作成部にドラッグ&ドロップし、それぞれをつないでいくことで、HTTPの入力から出力までのフローを作成していきます。
debugノードをつなげておき、右のデバッグタブを表示すると、デバッグできます。
フローの先頭から説明していきます。まずhttpノードを配置し、以下の設定をします。
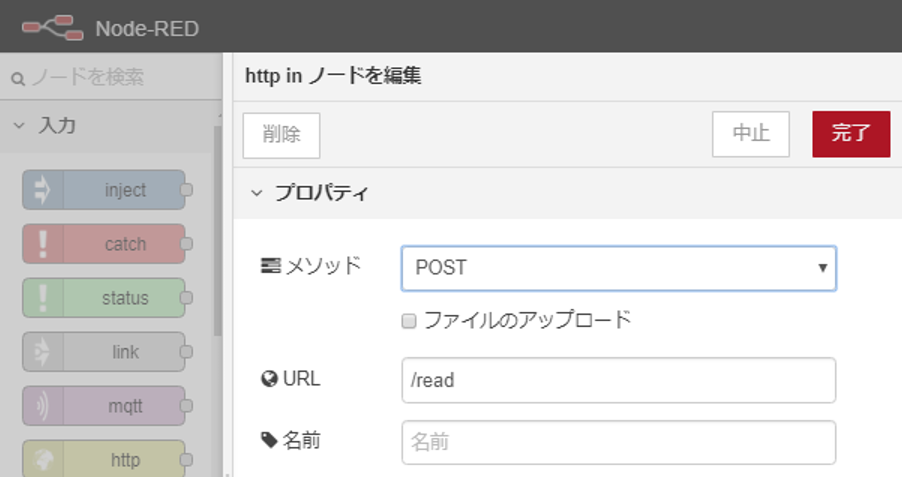
Webhookから来るHTTPリクエストはPOSTなので、メソッドはPOSTを選択します。そして、FulfillmentのURLの最後に付けた/readをここでもURL欄に設定します。
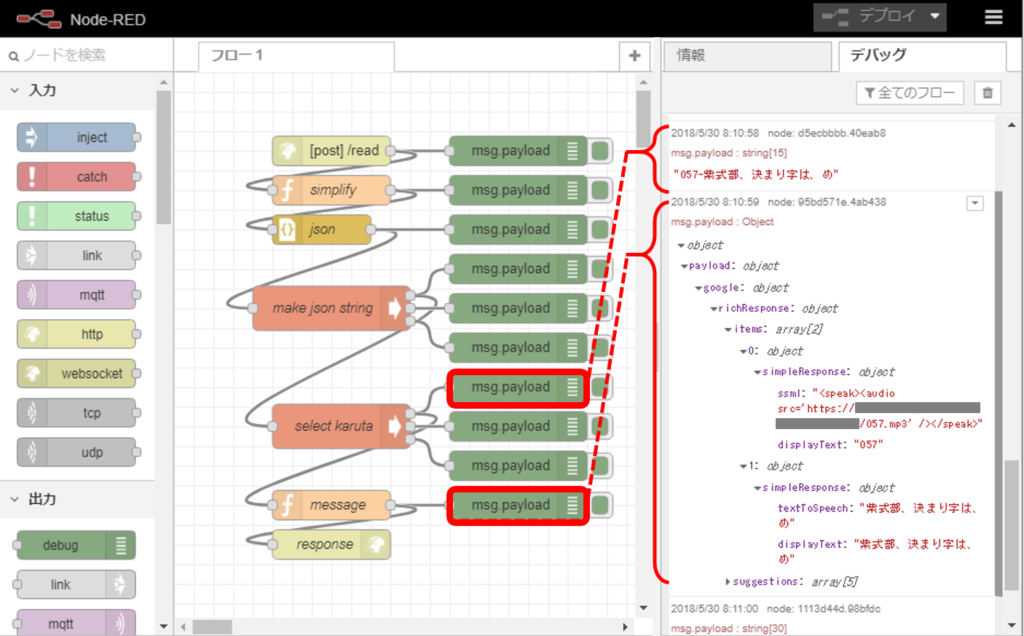
httpノードはWebhook経由で送られてくるJSONデータを受け取り、その内容はデバッグタブで確認できます。JSONデータは階層構造になっていて▶印をクリックして展開して中身を確認できるようになっています。
このJSONデータ構造はDialogflowのAPIバージョンで異なります。これは私もWebを参考にしていてハマりました。2018年6月現在、デフォルトはAPI V2で下図のようにDialogflowの上部にV1に切り替えるリンクがあります。この投稿ではV2を使用しています。

このアプリにおいて、「始め」と言われたのか「次」と言われたのかによって別のことをさせたかったので、Dialogflowのactionというパラメータに”init”または”next”を設定してWebhookを呼び出すことで区別するようにしました。
例えば前掲のフロー図においてデバッグタブ中queryResult.parameters.actionの値として”next”が送られてきたことがわかります。
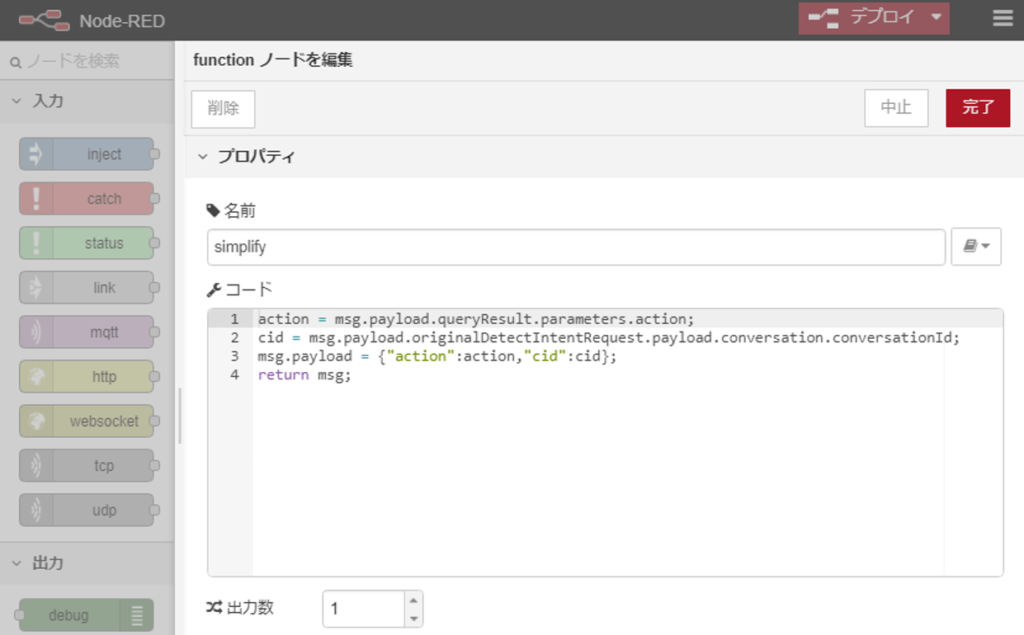
続いて、simplifyという名前をつけたfunctionノードが、JSONで送られてきたデータのうち必要なものだけにします。さきほどのactionに関して以下のようにmsg.payload.を付けて取り出すことができます。
また、会話のIDも使用したかったので、conversationIdを取得して、cidとして次のノードに渡しています。このconversationIdは、このアプリを開始して終了するまで同じ値が使用されます。
「次」と言われて、毎度ランダムに選択していると、すでに読んだ歌がまた読まれることがあります。これを防ぐためにアプリ開始時にランダムに読む順序を決めて、それをID付きのファイル名に保存し、さらにそのファイルの何番目まで来たのかを保存するファイルも作成します。「次」と言われたら、これらファイルを操作して決めた順序で歌を読んでいます。アプリ終了時にこれらファイルを削除して終わります。
前掲のフロー図デバッグタブの下の方を見ると、次に渡す情報がactionとcidの2つだけになっているのがわかります。
次にJSONデータを文字列に変換するjsonノードを次のように設定します。次のノードにコマンドライン引数としてactionとcidの値を渡すために利用しています。
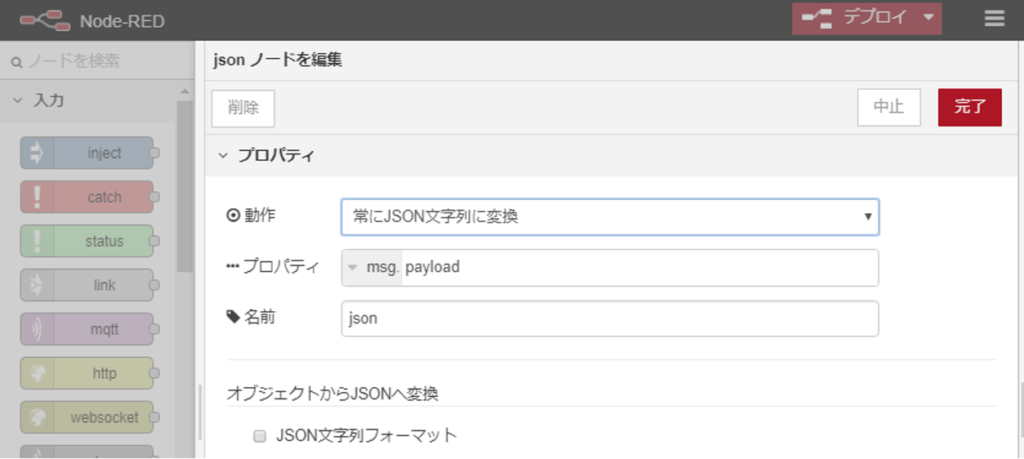
ここで、テキスト化された文字列を1つの引数として受け取れると思っていたのですが、{“action”:”next”,”cid”:”12345″} がLinuxサーバのシェルコマンドラインにおいてリストとして評価され、action:next と cid:12345 という2つの引数として次のノードに渡されていました。
そこで、make json stringという名前のexecノードから以下のシェルスクリプトを呼び出して action:next,cid:12345 という文字列に直し、次に渡すことにしました。
【run_karutaの中身】
#!/bin/sh echo $* | sed -e 's/ *//g' -e 's/[:,]/&/g'
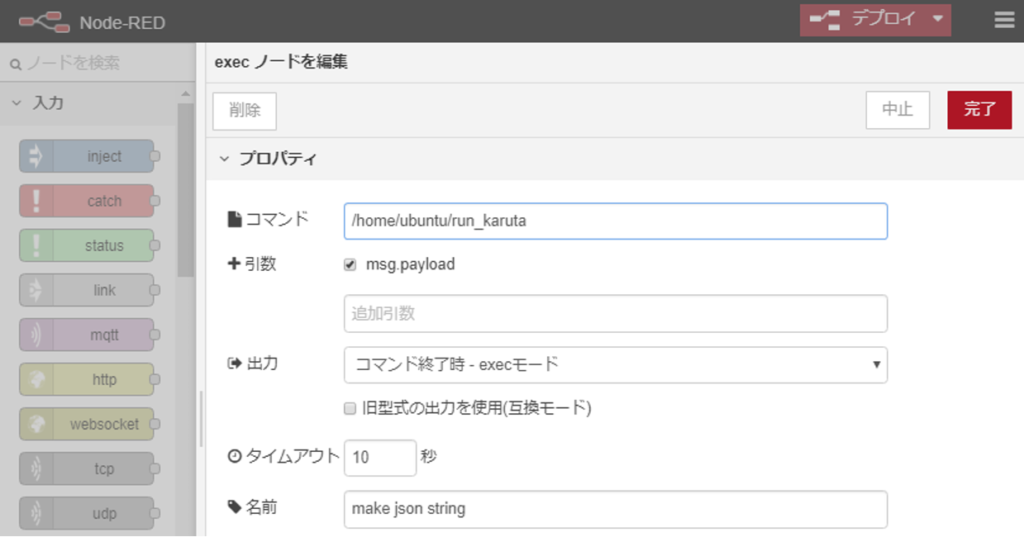
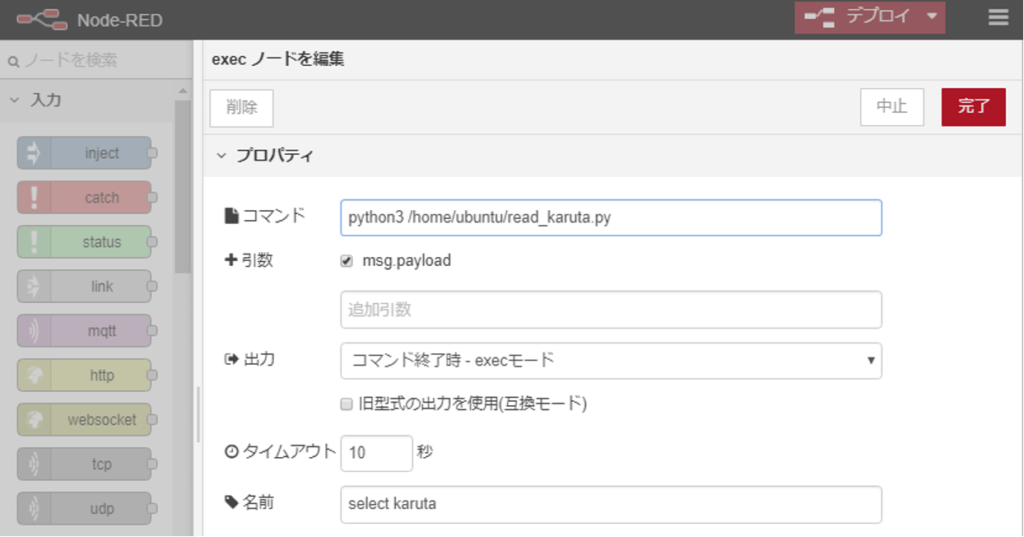
次のselect karutaという名前のexecノードがサーバ上のメインプログラムです。
【read_karuta.pyの中身(標準入力処理部と標準出力部の抜粋)】
lines = sys.argv[1]
lines = re.sub(r'[{}]', "", lines)
action = 'init'
cid = 0
for tmp1 in lines.split(','):
tmp2 = tmp1.split(':')
if tmp2[0] == 'action':
action = tmp2[1]
print('ACTION:' + action, file=sys.stderr, end=' ')
elif tmp2[0] == 'cid':
cid = tmp2[1]
print('CID:' + cid, file=sys.stderr, end=' ')
# <<< 省略 >>>
if action == 'next':
current += 1
if current == 100:
current = 99
f = open(fcurrent, 'w')
f.write('%d' % current)
f.close()
num = re.sub(r'[^0-9]*$', '', order[current])
print(num + '-' + explain[num], end='')
else:
print('000' + '-' + explain['000'], end='')
前のノードからactionとcidを受け取り、標準出力に”057-紫式部、決まり字は、め”のように歌番号と作者、決まり字の内容がハイフン(-)でつなげた文字列が出力されます。
これを続くmessageという名前のfunctionノードでDialogflowが読み取れる以下のJSON形式のデータを作成します。
itemsの最初のsimpleResponseとしてSSML形式でMP3ファイルのURLを送り、次のsimpleResponseのtextToSpeechの値として作者と決まり字を表す文字列を送っています。
suggestionsに次の入力候補を書いておくと、Actions on Googleによるテスト時に候補として表示されるようになり、マウスクリックで次の入力を行えるようになります。
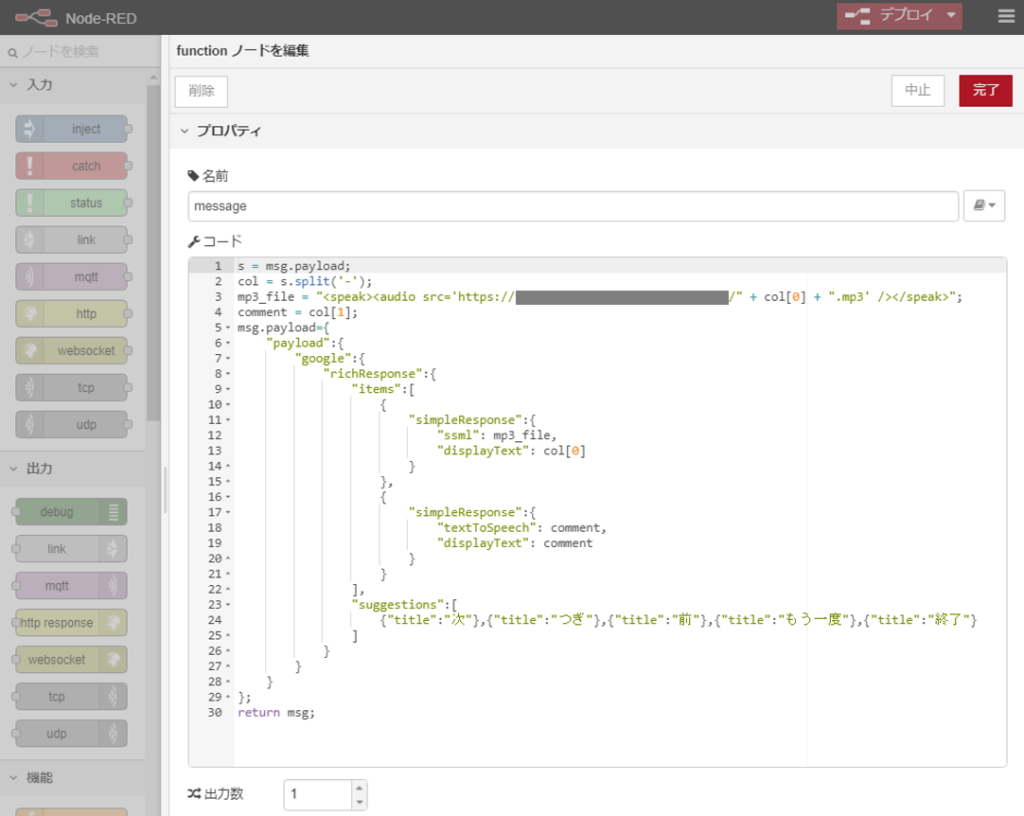
最後に以下のhttp responseノードに渡せば、Dialogflowにデータが送り返されます。
Node-REDのデバッグタブで以下のように確認できます。
Apacheの起動
音声ファイルの準備をします。使用するMP3音声データをクラウドサーバの以下のディレクトリ、または、その下にディレクトリを作って置きます。
/var/www/html
そして、apacheを起動します。コマンドラインから which apache2 または which httpd などで実行ファイルが見つかれば、apacheがインストール済みでパスが通っているので、以下のように管理者権限で実行します。
$ sudo apache2 start
上記はクラウドサーバにファイルを置く例ですが、Google Cloud Storageなどに置いたファイルのURLを指定して再生することもできるようです。
動作確認
ここまでできたら、Actions on Googleで動作確認をします。input欄に「かるた読みにつないで」「始め」「次」「終わり」のようにGoogle Homeに話す内容を記入して、意図通り動くか試します。
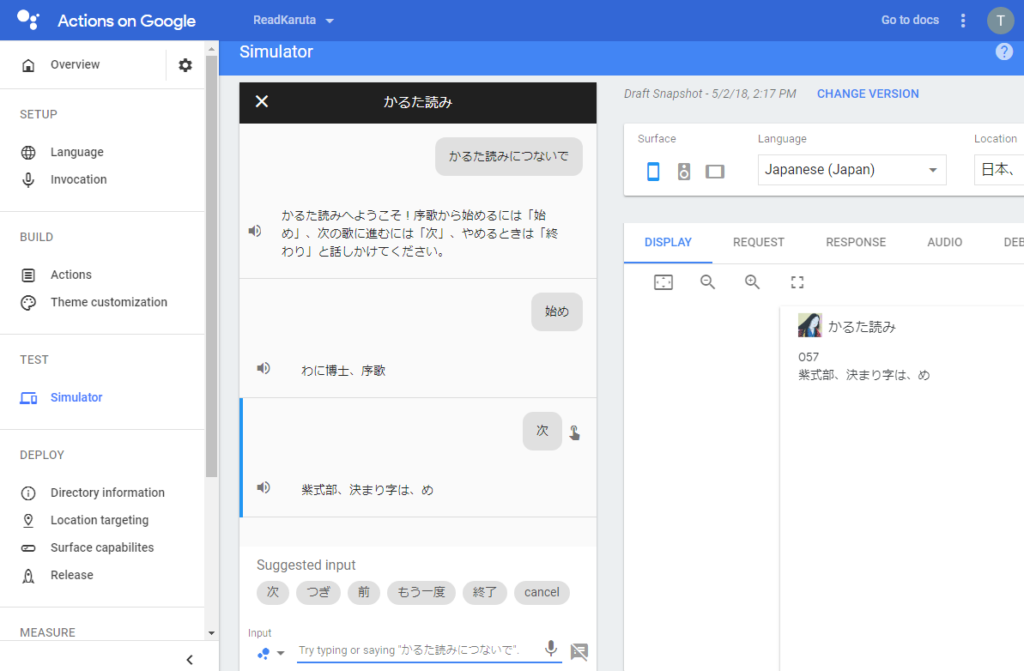
うまく動くことが確認出来たら、今度はGoogle Homeに話しかけます。システム概要の実行例のように読み上げてくれれば成功です。
おわりに
もっとスマートな実現方法があると思いますが、なんとか自分なりに想定する機能を実現することができました。
使っている音声データが個人使用のみ許可されているものなので、公開はしていません。
参考ページ
- Node-RED User Group Japan(https://nodered.jp/docs/)
- Actions on Google / SSML (https://developers.google.com/actions/reference/ssml)