

(2022/10/13更新)Ubuntu対応を追加したのと、OpenPose環境構築のコマンドを更新しました。
旧記事(Tensorflow 1.x)ではM1 Macでうまく動かない(zsh: illegal hardware instructionというエラーが出る)問題がありましたが、本記事の方法はM1 Mac/Intel Mac/Windows11/UbuntuでOpenPoseによる骨格推定を行えます。
OpenPoseはカーネギーメロン大学で開発された人物のポーズ推定ライブラリで、無料で利用することができます。(商用利用にはライセンス料が発生)
Pythonの環境であるAnaconda/Minicondaをベースに以下3つの入力に対しOpenPoseによる骨格推定をする方法を紹介します。
- 画像ファイル
- 内蔵カメラ(Windows11 WSL2環境はUSBカメラ)
- 動画ファイル
本記事の内容は、お使いのPCにGPU(グラフィックボード)が搭載されていても、いなくても、どちらでも動作します。
なお、元記事の方法はTensorflow 1.xを使用していましたが、Tensorflow 1.xはメンテナンスがされておらず、うまく環境構築できなかったため、Tensorflow 2.xを使用したOpenPoseのGitHubリポジトリを利用しました。
以下3つの動画に本記事の内容を実践した様子を収めていますので、よろしければご覧ください。
【Ubuntu用の動画】
【M1 Mac用の動画】
【Windows11用の動画】(ただし、OpenPose環境構築のコマンドが古いです)
動作環境
以下の環境で動作確認しました。
| (1) M1 Mac | (2) Intel Mac | (3) Windows PC | (4) Ubuntu | |
| PC | M1 MacBook Pro 2020 | Intel MacBook Pro 2015 | MSI GF65 15.6-inch | 自作PC(マザー:Z77H2) |
| OS | macOS Big Sur | macOS Monterey | Windows 11/WSL2 Ubuntu 20.04 LTS | Ubuntu 20.04 LTS |
| Anaconda | Miniconda 4.11.0 | Anaconda 4.11.0 | Anaconda 4.10.3 | Miniconda 4.14.0 |
| Python | 3.8.12 | 3.9.13 | 3.9.13 | 3.9.15 |
| OpenCV | 4.6.0.66 | 4.6.0.66 | 4.6.0.66 | 4.6.0.66 |
| Tensorflow | 2.10.0 | 2.10.0 | 2.10.0 | 2.10.0 |
事前準備
Mac(M1/Intel)の場合
HomeBrewをインストールしていない方は、以下のコマンドでインストールします。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
ここでbrewにパスを通すため、~/.zshrcを編集します。
vi ~/.zshrc
上記はviで編集していますが、他のテキストエディタでも構いません。
viの使い方を知りたい方は以下の動画を参考にしてください。
~/.zshrcに以下の1行を追記します。
export PATH="/opt/homebrew/bin:$PATH"
上記編集が終わったら、PATHの設定を反映させるため、以下を実行します。
source ~/.zshrc
wget(Webからファイルをダウンロード)とXquartz(X11ウィンドウを表示する)をインストールします。
brew install wget brew install --cask xquartz
ここでMacを再起動します。
Windows11の場合
WSL2のUtuntu-20.04 LTSをインストールして使用します。
Windowsマークを右クリック→Windowsターミナル(管理者)を立ち上げ、以下のコマンドでWSL2 Ubuntu-20.04 LTSをインストールします。
wsl --install -d Ubuntu-20.04
下図のようにプルダウンメニューからUbuntu-20.04を起動します。
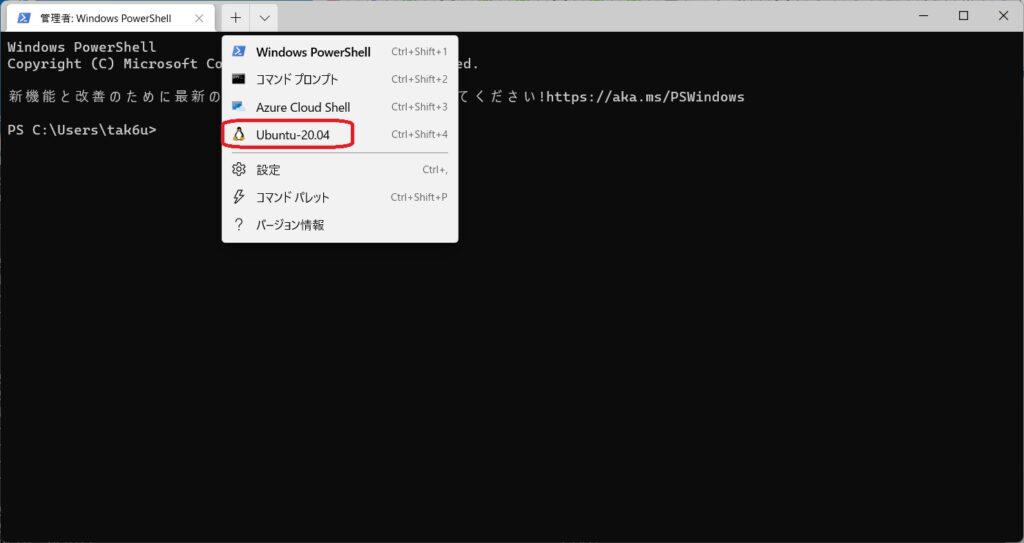
環境を更新しておきます。
sudo apt update sudo apt upgrade
Ubuntuの場合
環境を更新しておきます。
sudo apt update sudo apt upgrade
Anaconda/Minicondaインストール
GUIが無いMinicondaがおすすめですが、Anacondaを使用する場合はこちらのサイトの一番下にあるリンクから入手してインストールしてください。
Minicondaを使う場合は、MinicondaのGitHubから、お使いの環境に合ったリンクをクリックします。
| Intel Mac | Miniforge3-MacOSX-x86_64 |
| M1 Mac | Miniforge3-MacOSX-arm64 |
| Windows/WSL2 Ubuntu | Miniforge3-Linux-x86_64 |
| Ubuntu | Miniforge3-Linux-x86_64 |
Minicondaのインストールスクリプトをダウンロードしたら、以下のようにbashで実行します。(下記ファイル名はM1 Macの場合であり、OSによって異なります)
bash ~/Downloads/Miniforge3-〜.sh
以下のコマンドで初期化を行います。
source ~/.bashrc
~/.bashrcに自動的にMiniconda用の設定が追記されるので、sourceして有効にします。
これでターミナルのプロンプト(コマンド入力部の%や$より前の部分)に(base)が付くと思います。
condaをupdateしてバージョンを表示します。
conda update conda conda -V
以下のようにバージョンが表示されます。
conda 22.9.0
パッケージ一式を更新します。
conda update --all
Python 3.9を指定したposeという仮想環境を作成し、アクティベートします。
conda create -n pose python=3.9 conda activate pose
OpenPose環境構築
以降は、pose環境をアクティベートした状態でのコマンド入力になります。
必要なライブラリをインストールします。(M1 Mac以外)
pip --default-timeout=1000 install argparse dill fire matplotlib numba numpy psutil pycocotools requests scikit-image scipy slidingwindow tqdm swig tensorflow tensorpack tf-slim opencv-python
M1 Macのみ上記の代わりに以下を実行します。
pip --default-timeout=1000 install argparse dill fire matplotlib numba numpy psutil pycocotools requests scikit-image scipy slidingwindow tqdm tensorflow-macos tensorpack tf-slim opencv-python conda install swig
Tensorflow 2.x用のOpenPose環境をダウンロードします。
git clone https://github.com/gsethi2409/tf-pose-estimation.git cd tf-pose-estimation
以下のコマンドを順に実行してOpenPose環境を構築します。
cd tf_pose/pafprocess swig -python -c++ pafprocess.i && python3 setup.py build_ext --inplace cd ../.. cd models/graph/cmu bash download.sh cd ../../..
途中、swig〜コマンドの箇所で「warning: ‘tp_print’ is deprecated」というWarningが出ていても問題ありませんので、そのまま進めてください。
tf_pose/estimator.pyを編集します。
vi tf_pose/estimator.py
下記、”この行を追加”の行を追加します。
import logging import math import slidingwindow as sw import cv2 import numpy as np import tensorflow as tf import time from tf_pose import common from tf_pose.common import CocoPart from tf_pose.tensblur.smoother import Smoother from tensorflow.python.compiler.tensorrt import trt_convert as trt # Added tf.compat.v1.disable_eager_execution() # この行を追加 ((( 以降、省略 )))
OpenPose実行
以下のコマンドでサンプルとして付属されている画像を使ってOpenPoseを実行してみます。
python run.py --model=mobilenet_thin --resize=432x368 --image=./images/p2.jpg
以下のように表示されれば成功です。
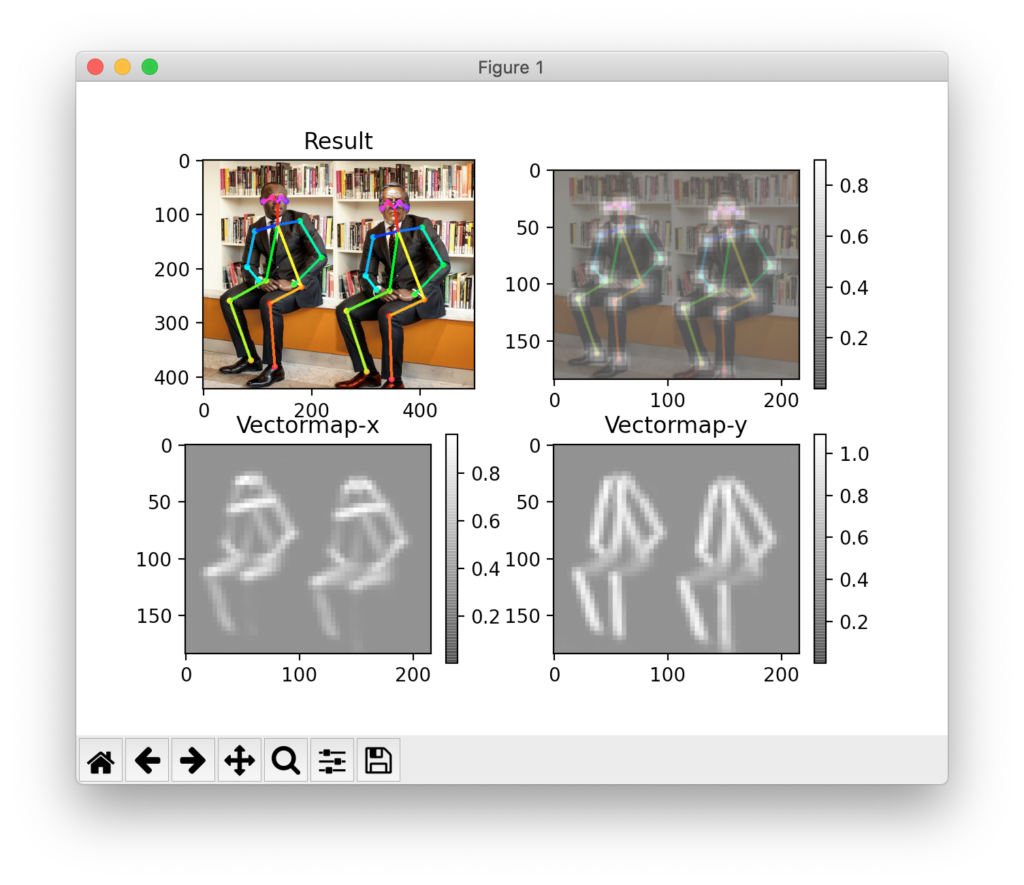
エラーが出る場合は、「トラブルシューティング」の章を参照してください。
左上の画像が骨格を元画像に重ね合わせた結果で、右上は関節の確度、下段は関節同士をつなぐためのX,Y方向のベクトルマップです。
--modelで指定できるモデルは、cmu / mobilenet_thin / mobilenet_v2_large / mobilenet_v2_small の4種類で、cmuはより正確に骨格を推定できるものの実行速度が遅いです。
他の3つはさほど変わらないように思えました。
--resizeオプションでサイズを432×368にしているのは、学習時の入力画像がこのサイズのため、この設定にすることで認識しやすくなるためのようです。
終了するにはqを押すか、表示されたウィンドウのX印を押します。
次に内蔵カメラやUSB接続したWebカメラを使ってリアルタイムのOpenPose実行を試します。
python run_webcam.py --model=mobilenet_thin --resize=432x368 --camera=0
以下のようにカメラ画像にリアルタイムに骨格が重ね合わせて表示されれば成功です。

骨格だけでなく、顔の中の目、耳、鼻の位置も捉えていることがわかります。
終了するにはターミナルでCtrl+cを押します。
最後に動画を入力とするrun_video.pyを試したのですが、うまく骨格が表示できなかったので、こちらのサイトの情報から、一部修正して以下をrun_video2.pyとして使用しました。
import argparse
import logging
import time
import cv2
import numpy as np
from tf_pose.estimator import TfPoseEstimator
from tf_pose.networks import get_graph_path, model_wh
logger = logging.getLogger('TfPoseEstimator-Video')
logger.setLevel(logging.DEBUG)
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
formatter = logging.Formatter('[%(asctime)s] [%(name)s] [%(levelname)s] %(message)s')
ch.setFormatter(formatter)
logger.addHandler(ch)
fps_time = 0
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='tf-pose-estimation Video')
parser.add_argument('--video', type=str, default='')
parser.add_argument('--write_video', type=str, default='')
parser.add_argument('--resize', type=str, default='0x0',
help='if provided, resize images before they are processed. default=0x0, Recommends : 432x368 or 656x368 or 1312x736 ')
parser.add_argument('--resize-out-ratio', type=float, default=4.0,
help='if provided, resize heatmaps before they are post-processed. default=1.0')
parser.add_argument('--model', type=str, default='mobilenet_thin', help='cmu / mobilenet_thin')
parser.add_argument('--show-process', type=bool, default=False,
help='for debug purpose, if enabled, speed for inference is dropped.')
parser.add_argument('--showBG', type=bool, default=True, help='False to show skeleton only.')
args = parser.parse_args()
logger.debug('initialization %s : %s' % (args.model, get_graph_path(args.model)))
w, h = model_wh(args.resize)
if w > 0 and h > 0:
e = TfPoseEstimator(get_graph_path(args.model), target_size=(w, h))
else:
e = TfPoseEstimator(get_graph_path(args.model), target_size=(432, 368))
cap = cv2.VideoCapture(args.video)
if args.write_video:
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
fmt = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
writer = cv2.VideoWriter(args.write_video, fmt, fps, (width, height))
if cap.isOpened() is False:
print("Error opening video stream or file")
while cap.isOpened():
ret_val, image = cap.read()
logger.debug('image process+')
humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=args.resize_out_ratio)
if not args.showBG:
image = np.zeros(image.shape)
logger.debug('postprocess+')
image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False)
logger.debug('show+')
cv2.putText(image, "FPS: %f" % (1.0 / (time.time() - fps_time)), (10, 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.imshow('tf-pose-estimation result', image)
if args.write_video:
writer.write(image)
fps_time = time.time()
if cv2.waitKey(1) == 27:
break
cv2.destroyAllWindows()
logger.debug('finished+')
入力する動画はPixaboyから最小サイズの640×360をダウンロードしました。
ファイル名が文字化けしていたので、45353.mp4という数字だけの名前に変えて、今いるディレクトリに移動します。
mv ~/Download/*45353.mp4 45353.mp4
以下のコマンドでダウンロードした動画を入力としてOpenPoseを実行します。
python run_video2.py --model=mobilenet_thin --resize=432x368 --video=45353.mp4
結果を動画ファイルに保存するには以下のように–write_video=<ファイル名>オプションを付けます。
python run_video2.py --model=mobilenet_thin --resize=432x368 --video=45353.mp4 --write_video=out.mp4
以下のように表示されれば成功です。
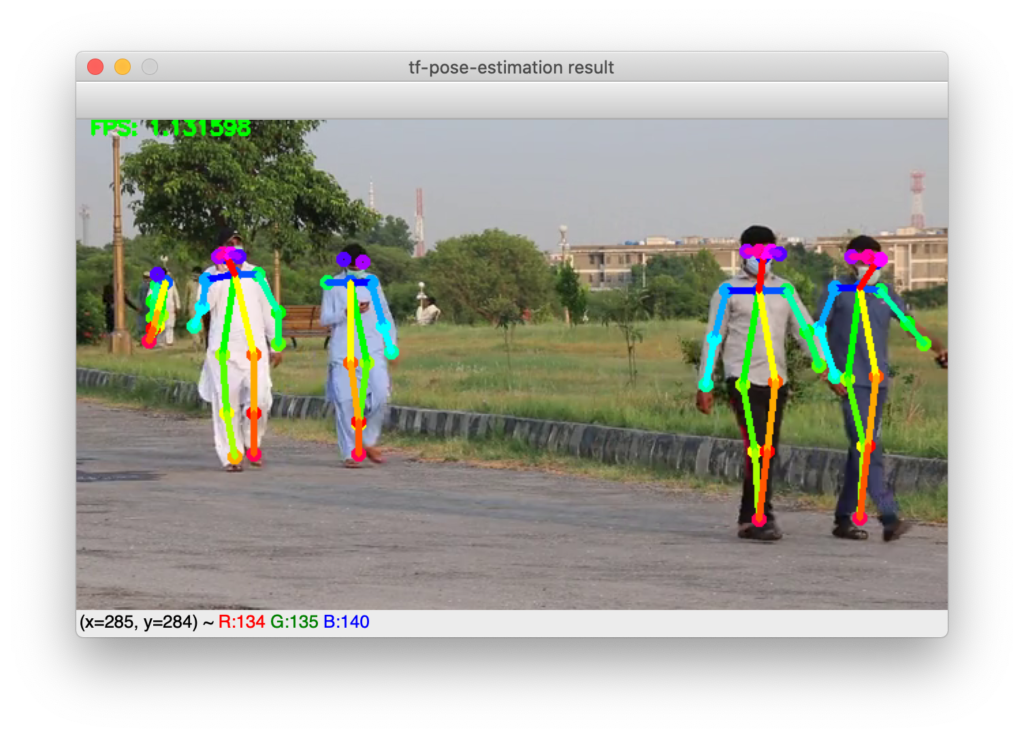
上図の場面では、水色の服の人は左腕が青い色の線になっていて、他の人とは左右反対です。
スマホを見ながら、うつむき加減でマスクも着用しているため、顔の認識ができず、後ろ向きと判断されてしまったようです。
このように誤認識してしまうケースもありますが、たいていは問題なく認識できています。
応用編
読者の方から、認識結果をファイルに落とす方法が知りたいとのご要望があり、run_video2.pyを少し発展させて以下のrun_video2_fileout.pyをサンプルとして作成しました。
import argparse
import logging
import time
import cv2
import numpy as np
from tf_pose.estimator import TfPoseEstimator
from tf_pose.networks import get_graph_path, model_wh
logger = logging.getLogger('TfPoseEstimator-Video')
logger.setLevel(logging.DEBUG)
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
formatter = logging.Formatter('[%(asctime)s] [%(name)s] [%(levelname)s] %(message)s')
ch.setFormatter(formatter)
logger.addHandler(ch)
fps_time = 0
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='tf-pose-estimation Video')
parser.add_argument('--video', type=str, default='')
parser.add_argument('--write_video', type=str, default='')
parser.add_argument('--resize', type=str, default='0x0',
help='if provided, resize images before they are processed. default=0x0, Recommends : 432x368 or 656x368 or 1312x736 ')
parser.add_argument('--resize-out-ratio', type=float, default=4.0,
help='if provided, resize heatmaps before they are post-processed. default=1.0')
parser.add_argument('--model', type=str, default='mobilenet_thin', help='cmu / mobilenet_thin')
parser.add_argument('--show-process', type=bool, default=False,
help='for debug purpose, if enabled, speed for inference is dropped.')
parser.add_argument('--showBG', type=bool, default=True, help='False to show skeleton only.')
args = parser.parse_args()
logger.debug('initialization %s : %s' % (args.model, get_graph_path(args.model)))
w, h = model_wh(args.resize)
if w > 0 and h > 0:
e = TfPoseEstimator(get_graph_path(args.model), target_size=(w, h))
else:
e = TfPoseEstimator(get_graph_path(args.model), target_size=(432, 368))
cap = cv2.VideoCapture(args.video)
if args.write_video:
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
fmt = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
writer = cv2.VideoWriter(args.write_video, fmt, fps, (width, height))
with open('humans.txt', mode='w') as f:
if cap.isOpened() is False:
print("Error opening video stream or file")
while cap.isOpened():
ret_val, image = cap.read()
if ret_val:
logger.debug('image process+')
humans = (e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=args.resize_out_ratio))
#print(humans)
#print(type(humans))
#print(len(humans))
#exit(0)
tmp_h = []
for human in humans:
tmp_h.append(str(human))
str_h = ";".join(tmp_h)
print(str_h)
f.write(str_h)
f.write("\n")
#exit(0)
if not args.showBG:
image = np.zeros(image.shape)
logger.debug('postprocess+')
image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False)
logger.debug('show+')
cv2.putText(image, "FPS: %f" % (1.0 / (time.time() - fps_time)), (10, 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.imshow('tf-pose-estimation result', image)
if args.write_video:
writer.write(image)
fps_time = time.time()
if cv2.waitKey(1) == 27:
break
else:
break
cv2.destroyAllWindows()
logger.debug('finished+')
認識結果はhumansにHumanクラスのインスタンスのリストとして格納されていました。
humansの中身を確認した際のコードもコメントとして残してあります。
Humanクラスはtf_pose/estimator.pyに定義されています。
実行方法は同様で以下のように使用します。
python run_video2_fileout.py --model=mobilenet_thin --resize=432x368 --video=45353.mp4
実行するとhumans.txtというファイルができて、以下のようにBodyPart:0〜17の座標(画角に対し0〜1に正規化した値)とscore(確信の度合いと思われる)が空白区切りで出力されます。
BodyPart:0-(0.50, 0.30) score=0.88 BodyPart:1-(0.50, 0.33) score=0.84 ...
人が認識される個数は入力する絵によって異なります。複数認識の場合、それぞれをセミコロン(;)で区切るようにしてあります。
BodyPartは毎度0〜17のすべてが出力される訳ではないようです。
このようにテキストに落としてしまえば、外部でいろいろ処理ができそうです。
もっと情報をしぼって出力したい場合は、tf_pose/estimator.pyの中身を見てTfPoseEstimatorクラスのdraw_humansメソッドを参考に、human.body_parts[i].xのようにコアなデータにアクセスするコードを書くのが良いと思います。
トラブルシューティング
KeyErrorが出る
tf_pose/estimator.pyをダウンロードしたままにすると、以下のエラーが出てしまします。
KeyError: "The name 'TfPoseEstimator/image:0' refers to a Tensor which does not exist. The operation, 'TfPoseEstimator/image', does not exist in the graph."
「OpenPose環境構築」の章に記載のとおり、1行追加が必要です。
CuDNNのエラーが出る
環境によっては以下のエラーが出る場合があります。
2022-10-09 16:21:35.989994: F tensorflow/stream_executor/cuda/cuda_dnn.cc:217] Check failed: status == CUDNN_STATUS_SUCCESS (7 vs. 0)Failed to set cuDNN stream. Aborted
これの対策として、tf_pose/common.pyに下記”以下2行を追加”に続く2行を追記します。
from enum import Enum
import tensorflow as tf
import cv2
regularizer_conv = 0.004
regularizer_dsconv = 0.0004
batchnorm_fused = True
activation_fn = tf.nn.relu
# 以下2行を追加
physical_devices = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
((( 以下、省略 )))
また、上記の代わりに以下のコマンドを実行して、GPUを使わないようにすることでも解決できます。
export CUDA_VISIBLE_DEVICES=""
まとめ
M1 Mac/Intel Mac/Windows11/Ubuntu 20.04でAnaconda/MinicondaをベースにOpenPoseで骨格推定を行える環境の構築を行い、以下3種の入力に対しOpenPoseを実行することができました。
- 画像ファイル
- 内蔵カメラ(Windows11 WSL2環境はUSBカメラ)
- 動画ファイル
このようにOpenPoseを使うと単眼カメラの画像から骨格を2Dの座標情報として推定し、画像に重ね合わせて表示することができました。
人物に骨格を重ね合わせて表示されるのはとても楽しいので、是非お試しください。
ものづくりに興味があり、いろいろ触り始めたらLinuxの知識が必要になって困っているという方向けに以下のページを作成しましたので、よろしければ参考にしてください。

(参考)旧環境構築コマンドのバックアップ
以前は以下のコマンドで環境構築していたのですが、2022年10月に試すと動かなくなっていたため、「OpenPose環境構築」の章に記載の内容に置き換えました。
旧コマンドを記録のために残しておきます。
conda install numba scipy pip install -r requirements.txt conda install -c conda-forge tensorflow conda install swig cd tf_pose/pafprocess swig -python -c++ pafprocess.i && python3 setup.py build_ext --inplace cd ../.. conda install -c conda-forge opencv pip install git+https://github.com/adrianc-a/tf-slim.git@remove_contrib cd models/graph/cmu bash download.sh cd ../../..
以前は、condaを使ってインストールするものとpipを使うもの混在していましたが、結局すべてpipにすることでコマンドを簡単にできたので「OpenPose環境構築」の内容に置き換えました。
すべてpipならAnaconda/Minicondaを使う必要ないのでは?と思うかもしれませんが、次点候補のpipenvでの構築も試したのですが、TimeOutエラーが解消できず、結局すべてpipでのインストールであってもAnaconda/Minicondaが使いやすいというのが、2022年10月現在の私の意見です。
書籍紹介
Pythonや画像処理、機械学習関連のおすすめ書籍を紹介します。

実践して楽しむことを重視していて、充実のサンプルコードで画像認識やテキスト分析、GAN生成といったAI応用をGoogle Colab環境下で体験できます。

基礎から応用までわかりやすい説明でコード例も多数載っていて、初学者の入門書としては必要十分と感じています。
さらにPythonらしいコードの書き方も言及されていて、スマートなコードが書けるようになります。
詳解 OpenCV 3 ―コンピュータビジョンライブラリを使った画像処理・認識

最新のOpenCV4には対応していないのですが、やはりオライリー、基礎を学ぶには十分な情報があり、この本から入ることをおすすめします。
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装

この本は、機械学習の仕組みを学ぶのにとても良い本だと思います。
Tensorflow/Kerasなどの既存プラットフォームを使うのではなく、基本的な仕組みを丁寧に説明し、かんたんなPythonコードで実装していく手順を紹介してくれます。
機械学習のコードがどのような処理をしているのか、想像できるようになります。
参考文献
- Pose Estimation with TensorFlow 2.0(https://medium.com/@gsethi2409/pose-estimation-with-tensorflow-2-0-a51162c095ba)
- 【Python】Anaconda上にOpenCVをインストールする方法【Windows】(https://qiita.com/osakasho/items/c9d87b70e8f043569ca7)
- pip で Numba をインストールする時にエラーになる(https://va2577.github.io/post/70/)
- OpenPoseで骨格推定【Mac】 Anaconda/OpenCV/TensorFlow(https://take6shin-tech-diary.com/openpose-mac/)