
はじめに
NVIDIAのGPUを搭載した少し古いMacを機械学習マシンにしようと環境設定をトライしたもののうまく動かせずに終わってしまった方も多いのではないでしょうか。
まず、2012〜2014年のMacBook Proに搭載されているGPUはNVIDIA GeForce GT 650M/750Mで、すでに時代遅れであることやインストールすべきツール群の依存関係が難しく、うまく動く組み合わせが限られていることが、環境構築が難しい要因です。
私もかなりの時間を費やしてやっとの思いでこの記事の方法にたどり着きました。
この記事では、NVIDIAのGPUを搭載したMacBook ProにデュアルブートでUbuntu Linuxをインストールし、Ubuntu側にCUDA/cuDNN/Tensorflow機械学習環境を構築する方法を紹介します。
構築した環境での機械学習の処理速度は、最新MacBook(Core i9 8Core)と比べると少し遅いという結果でした。
高価なマシンと同程度の処理速度が出せると考えるとコストメリットがあると捉えることもできますね。
NVIDIAのGPU搭載Mac
最近のMacにはNVIDIAのGPUが載っておらず、機械学習には不向きとされていますが、少し古い一部のMacBook Pro 15-inchにはNVIDIAのGPUが搭載されていて、こちらを使ってGPUを使用する機械学習環境を構築しました。(下表はこちらより引用)
| Mac | macOS 10.14 Mojave macOS 10.15 Catalina | Catalina対応かつNVIDIA製GPUを搭載したMac |
|---|---|---|
| MacBook | 2015以降 | なし |
| MacBook Air | 2012以降 | なし |
| MacBook Pro | 2012以降 | MacBook Pro (Retina, 15-inch, Mid 2012) MacBook Pro (Retina, 15-inch, Early 2013) MacBook Pro (Retina, 15-inch, Late 2013) MacBook Pro (Retina, 15-inch, Mid 2014) |
| Mac mini | 2012以降 | なし |
| iMac | 2012以降 | iMac (21-/27-inch, Late 2012) iMac (21.5-/27-inch, Late 2013) |
| iMac Pro | 2017以降 | なし |
| Mac Pro | Metalと互換性のあるGPUを積んだMid 2010/Mid 2012以降(Catalinaは2013以降) | なし |
こちらによると2020年5月時点最新のmacOS CatalinaではNVIDIAの機械学習プラットフォームであるCUDAやcuDNNを使えず、High Sierraまで落とさなければいけないとのこと。
今さらHigh Sierraまでダウングレードする気がしなかったので、こちらを参考にデュアルブートでUbuntuを入れる方法を採用しました。
ホストOSとしてのUbuntuにはNVIDIAドライバとnvidia-container-toolkitのパッケージをインストールし、CUDA、cuDNN、TensorflowはDockerコンテナに構築します。
また、最近の高性能Macと比較してGPUの実力はどの程度なのか、またGoogleの無料機械学習環境Google Colabとの性能比較にも興味があったので、ベンチマークしてみました。結果はGoogle Colabの圧勝な訳ですが・・・
動作環境
NVIDIAのGPUがサポートする機能を識別するためのバージョン番号であるcompute capabilityが各GPUに割り当てられていて、こちらから製品名をクリックすることで調べられます。
今回使用したMacBookに搭載されているGPUは、GeForce GT 650M/750Mで、いずれもcompute capabilityは3.0でした。
Tensorflowはcompute capability 3.0以上に対応すると謳って入るものの、pip等のパッケージ管理ツールによりバイナリで提供されるTensorflowはcompute capabilityが3.5以上に対応しており、GeForce GT 650M/750MでTensorflowを実行するためにはソースからビルドする必要がありました。
デフォルトで未対応ということは、すでに時代遅れのGPUということだと思うので、底辺レベルのGPU環境を構築したと言えるでしょう。
| Item | (1) MBP Mid 2012 w/ GT 650M | (2) MBP Late 2013 w/ GT 750M |
|---|---|---|
| PC | MacBook Pro 15-inch Mid 2012 | MacBook Pro 15-inch Late 2013 |
| CPU | Intel Core i7 3615QM 2.3GHz | Intel Core i7 4850HQ 2.3GHz |
| Graphic Board | NVIDIA GeForce GT 650M 1GB | NVIDIA GeForce GT 750M 2GB |
| Wi-Fi Module | Broadcom BCM4331 | Broadcom BCM4360 |
| OS | Ubuntu 18.04LTS (Dual Boot) | ← |
| NVIDIA Driver | 440.64.00 | 450.36.06 |
| Docker | 19.03.9 | 19.03.11 |
| Docker-compose | 1.25.5 | ← |
| CUDA | 10.0 | ← |
| cuDNN | 7.6.5 | ← |
| Tensorflow | tensorflow_gpu-1.14.0 | ← |
| Keras | 2.2.4-tf (Tensorflow embedded) | ← |
こちらのバージョン対応表(GPU)と異なるのはcuDNNのみで、テスト済みとしは7.4となっていますが、7.6.5でも大丈夫でした。
Ubuntu 18.04LTSデュアルブート環境の構築
こちらを参考にmacOSとUbuntuのデュアルブート環境を構築します。
Ubuntu起動メディアの作成
こちらからUbuntu 18.04のdesktop imageをダウンロードし、Etcherなどで.isoファイルをUSBメディアやSDカードなどに書き込みます。
Ubuntu用パーティションの作成
Command+Rを押しながら電源を入れ、リカバリーモードでMacを起動します。ディスクユーティリティを立ち上げ、内蔵ディスクのトップを選択して「パーティション作成」ボタンを押します。(「ボリュームを追加」ボタンではありません)
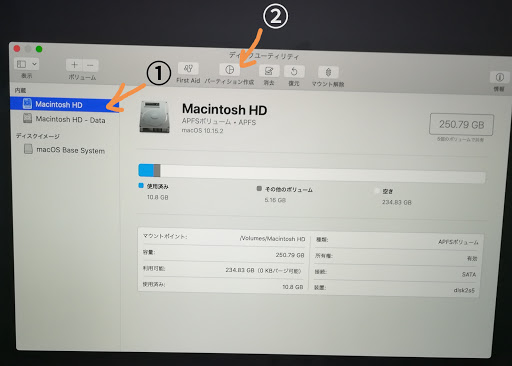
円グラフの下にある「+」ボタンを押し、パーティションに”UBUNTU”などのように名前を付け、フォーマットはMS-DOS (FAT32)を選択します。
ディスク容量の比率は円グラフの円周上にある○印を動かすことで変更できます。
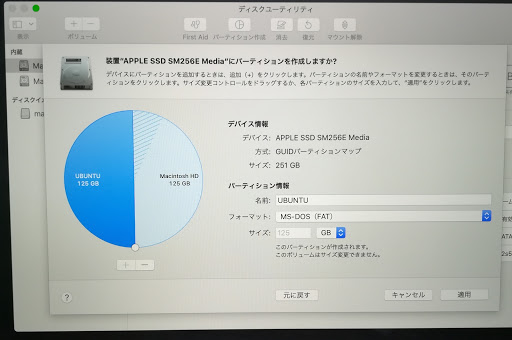
「適用」→「パーティション作成」を押します。
パーティション作成の処理(少し時間がかかります)が終わり、以下のように表示されれば成功です。
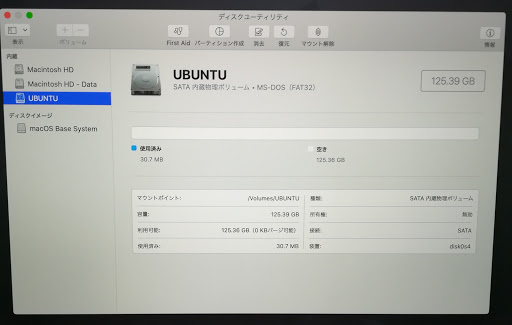
お使いのマシンによっては、PCI物理ボリュームAPFSのように表示される場合があるかもしれませんが、上記でMS-DOS(FAT)を選択していれば問題ありません。
アップルマークからシステム終了を選択して電源を落とします。
Ubuntuインストール
上で作成したメディアをPCにセットし、Optionキーを押しながら電源ボタンを押し、起動ディスク選択モードでMacを立ち上げます。

Ubuntuインストールメディアを選択し(EFI Bootが2つ出ますがどちらでも良いようです)、その後表示される黒い画面では一番上の”Try Ubuntu without installing”を選択してEnterを押すか、そのまま待っているとUbuntuが起動します。左上にあるインストールアイコンをクリックし、インストールを開始します。
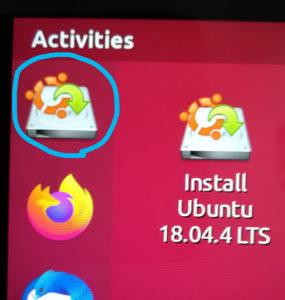
まず言語を聞かれますが、ここで日本語を選択すると”Download”などのディレクトリ名が”ダウンロード”と日本語になってしまい、コマンドラインの使い勝手が悪くなってしまうので、Englishを選択しておく方が良いと思います。日本語入力はインストール後に設定できます。
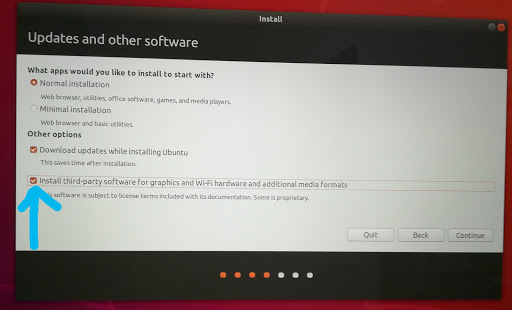
キーボード選択後の以下の画面では”Install third-party…”にチェックを入れContinueを押します。
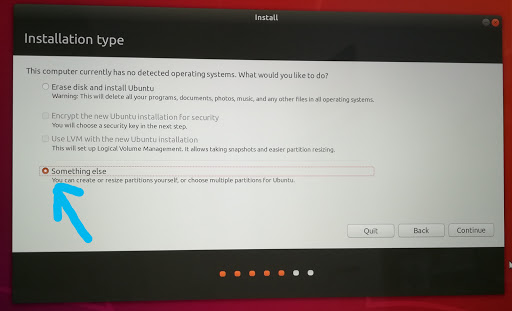
作成したパーティションにインストールするため、”Something else”を選択します。
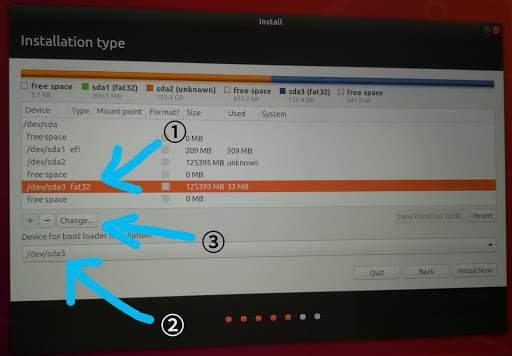
追加作成したパーティションのディスクを選択し、Changeを押します。
お使いのマシンによっては、下図のようにTypeがfat32と表示されない場合がありますが、ディスクサイズを参考にするなどして特定してください。
追加作成したディスクのデバイス名は/dev/sda3などのように元からあったディスクよりsdaに続く数値が大きくなっていると思われます。
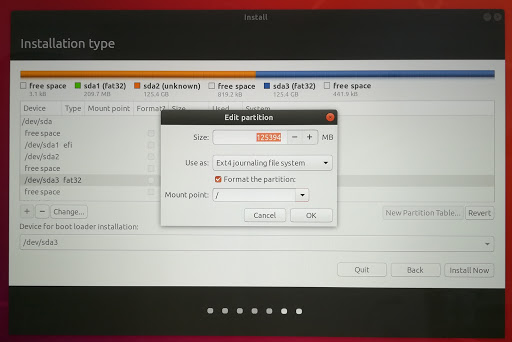
以下のようにUse as:はExt4 journaling file systemを選択、Format the partition:にチェックを入れ、Mount point:に / (スラッシュ)を入れ、「Install Now」ボタンを押します。
以下のようなポップアップが出ますが、気にせず「Continue」ボタンを押します。
ユーザ名、PC名、パスワードを設定するとインストールが開始されます。
再起動を促すメッセージが出たら、インストールメディアを抜き、再起動します。
もし黒い画面で止まったらCtrl+Cで再起動が続行するようです。
以降、電源ボタンを押して通常通りMacを起動するとUbuntuが立ち上がります。macOSを立ち上げたい場合はOption+電源ボタンで起動します。
Caps lockをCtrlに変更
画面左下の9つのドットのアイコンから、もしくはCtrl+Option+TでTerminalを立ち上げ、/etc/default/keyboardファイルを編集します。
以降、テキストファイルの編集はviエディタを使う前提で説明していますが、viに不慣れな方は↓の動画で最低限のテキスト編集の方法を紹介しているので参考にしてください。
$ sudo vi /etc/default/keyboard
以下のようにXKBOPTIONS="ctrl:nocaps"の行を追加します。
すでにXKBOPTIONSの行が存在する場合は設定内容を置き換えます。
XKBLAYOUT="us" BACKSPACE="guess" XKBOPTIONS="ctrl:nocaps"
下記Wi-Fi設定後に再起動するとCaps lockキーがCtrlになります。
Wi-Fiの設定
ここで説明する内容は、Thunderbolt-LAN変換アダプタ経由でインターネットに有線接続してあることが前提の方法になっています。
なお、Wi-FiデバイスはBCM4331やBCM4360などのBroadcomのデバイスが内蔵されたPCでの設定方法となっておりますのでご注意ください。
Wi-Fiデバイスはlspci | grep Wirelessなどのコマンドで確認できます。
$ sudo apt-get update $ sudo apt-get upgrade $ sudo apt-get install broadcom-sta-dkms $ sudo reboot
有線LANケーブルを抜き再起動したら画面右上の▼印からWi-FiのSSID、パスワード設定を行います。
入力設定
Settings→Region & Languageの「Manage Installed Languages」ボタンを押すと追加のインストールを促すメッセージが出るのでインストールして再起動します。
これでJapanese (Mozc)が選べるようになります。
+ボタンからJapanese (Mozc)を追加します。 メニューのenの横にある▼印でJapanese (Mozc)を選び、画面右上の▼印からInput ModeをHiraganaにします。
これでCommand+Spaceで半角と日本語入力が切り替わるようになりますが、お好みでDevices→Keyboard設定のTypingからCtrl+Spaceなどに変更できます。
NVIDIAドライバのインストール
以降の作業に役立つファイルをGitHubに登録してあるので、よろしければお使いください。
gitをインストール済みの場合は下記最初の行は不要です。
$ sudo apt-get install git $ git clone https://github.com/tak6uch1/cuda-tensorflow
こちらに従い、cuda-driversをUbuntuにインストールします。
以下のコマンドを実行するか、GitHubからcloneした場合は、install_nvidia_driver.shを実行します。
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin $ sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600 $ sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub $ sudo add-apt-repository "deb http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/ /" $ sudo apt-get update $ sudo apt-get -y install cuda-drivers
再起動後、以下のようにnvidia-smiコマンドでGPU情報が表示されれば問題ありません。
$ nvidia-smi
Sat May 16 10:17:30 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.64.00 Driver Version: 440.64.00 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GT 650M On | 00000000:01:00.0 N/A | N/A |
| N/A 50C P8 N/A / N/A | 372MiB / 981MiB | N/A Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 Not Supported |
+-----------------------------------------------------------------------------+
ただし、GeForce GT 650Mはプロセス表示には対応していないため、上記のようにNot Supportedと表示されます。
GeForce GT 750Mの場合は以下のように表示されました。
$ nvidia-smi
Tue Jun 23 01:53:33 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.36.06 Driver Version: 450.36.06 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce GT 750M On | 00000000:01:00.0 N/A | N/A |
| N/A 70C P1 N/A / N/A | 579MiB / 1999MiB | N/A Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Dockerのインストール
こちらによるとnvidia-dockerやnvidia-docker2コマンドは過去の方法で、通常のDocker(19.03以降)を使うのが良いとのことなのでそれに従います。
以下のコマンドでDockerをインストールします。
curlをすでにインストールしてある場合は1行目は不要です。
3行目はsudo無しでDockerを実行できるようにするための処置です。
$ sudo apt-get install curl $ curl https://get.docker.com | sh $ sudo usermod -aG docker $USER $ sudo reboot
再起動し、下記のようにDockerのバージョンが表示されれば成功です。
$ docker --version Docker version 19.03.8, build afacb8b7f0
こちらによるとdocker-composeはnative GPU supportされていないとのことですが、他の用途で使いそうなのでdocker-composeはインストールしておきました。
まず、以下のサイトで最新のバージョンを確認します。Pre-releaseとなっているものよりLatest releaseの方が安心かと思います。
https://github.com/docker/compose/releases
以下コマンドの1.25.5の部分を使用するバージョンに置き換えて実行します。
$ sudo curl -L https://github.com/docker/compose/releases/download/1.25.5/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose $ sudo chmod +x /usr/local/bin/docker-compose
以下のようにバージョンが表示されれば成功です。
$ docker-compose --version docker-compose version 1.25.5, build 8a1c60f6
Nvidia-container-toolkitのインストール
こちらのUbuntu用の指示に従い、nvidia-container-toolkitをインストールします。
以下のコマンドを実行するか、GitHubからcloneした場合は、install_nvidia_container_toolkit.shを実行します。
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) $ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - $ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list $ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit $ sudo systemctl restart docker
nvidia-container-cli infoを実行して以下のように表示されればインストール成功です。
$ nvidia-container-cli info NVRM version: 440.64.00 CUDA version: 10.2 Device Index: 0 Device Minor: 0 Model: GeForce GT 650M Brand: GeForce GPU UUID: GPU-67f4e3bb-1ffc-481a-3bd5-b181359c583e Bus Location: 00000000:01:00.0 Architecture: 3.0
再起動してDocker環境構築に進みます。
Docker環境構築
Tensorflowの対応表とこちらを参考にDockerfileとMakefileを作成しました。
Makefileはよく使うDocker関連のコマンドを少ないキー入力で実行するためのものです。
シェルスクリプト化したりエイリアスするなど他の方法でも実現できます。
以下のURLからUbuntu 18.04用で名前にcudnnが入っているものを探し、CUDA/cuDNNイメージをベースにTensorflow_gpu/Kerasを追加していきます。https://hub.docker.com/r/nvidia/cuda/tags
以降、Ubuntuホストマシンでの実行とDockerコンテナ内の実行を区別するため、プロンプトを以下のように分けて表現します。
Ubuntu:$
Dockerコンテナ:%
Dockerfile
以下、Dockerfileの例です(GitHubからも取得できます)。
BazelはGoogle社開発のビルドツールで、Tensorflowをソースからビルドするのに使用します。
コンテナを起動したらJupyter Notebookを立ち上げるようにしてあります。
FROM nvidia/cuda:10.0-cudnn7-devel-ubuntu18.04
# User info
ARG USER=user
ARG GROUP=user
ARG PASS=password
ENV DEBIAN_FRONTEND=noninteractive
RUN apt update && apt install -y --no-install-recommends \
apt-utils \
bzip2 \
curl \
gcc-4.8 \
g++-4.8 \
gnupg \
git \
less \
libbz2-dev \
libssl-dev \
lsof \
openssl \
unzip \
vim \
wget
# Install Python
#RUN apt update && apt install -y python-dev python-pip
RUN apt update && apt install -y python3-dev python3-pip
RUN pip3 install -U pip six 'numpy<1.19.0' wheel setuptools mock 'future>=0.17.1'
RUN pip3 install -U keras_applications --no-deps
RUN pip3 install -U keras_preprocessing --no-deps
# Install Bazel
RUN wget https://github.com/bazelbuild/bazel/releases/download/0.24.1/bazel-0.24.1-installer-linux-x86_64.sh
RUN chmod +x bazel-0.24.1-installer-linux-x86_64.sh
RUN ./bazel-0.24.1-installer-linux-x86_64.sh
# Install Tensorflow
RUN git clone https://github.com/tensorflow/tensorflow.git
WORKDIR tensorflow
RUN git checkout r1.14
ADD .tf_configure.bazelrc .
ENV TMP=/tmp
RUN ln -s /usr/bin/python3 /usr/bin/python
RUN bazel build --config=opt --config=cuda //tensorflow/tools/pip_package:build_pip_package
RUN ./bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
RUN pip3 install /tmp/tensorflow_pkg/tensorflow-*.whl
# Install python library
RUN pip3 install --ignore-installed \
jupyter \
graphviz \
matplotlib \
notebook \
pandas \
h5py \
pydot \
scikit-learn \
SciPy \
jupyter_contrib_nbextensions
# Enable nbextension
RUN jupyter contrib nbextension install --user
RUN mkdir /opt/notebooks
# Add user
RUN groupadd -g 1000 $GROUP
RUN useradd -g $GROUP -G sudo -m -s /bin/bash $USER
RUN echo "${USER}:${PASS}" | chpasswd
RUN echo "root:${PASS}" | chpasswd
RUN echo 'alias ls="ls -a --color=auto --show-control-chars --time-style=long-iso -FH"' >> /home/$USER/.profile
RUN echo 'alias ll="ls -a -lA"' >> /home/$USER/.profile
RUN echo 'alias h=history' >> /home/$USER/.profile
RUN echo 'alias vi=vim' >> /home/$USER/.profile
RUN echo 'PS1="% "' >> /home/$USER/.bashrc
RUN echo 'set background=dark' > /home/$USER/.vimrc
RUN echo 'syntax on' >> /home/$USER/.vimrc
# Clean cache
RUN apt-get clean && \
rm -rf /var/lib/apt/lists/* && \
rm -rf /tmp/*
WORKDIR /
EXPOSE 8888
# Run jupyter notebook.
CMD ["jupyter", "notebook", "--notebook-dir=/opt/notebooks", "--ip='*'", "--port=8888", "--no-browser"]
USER, GROUP, PASSはホストマシンのユーザに合わせて変更してください。
ADDで追加している.tf_configure.bazelrcの中身は以下です(GitHubからも取得できます)。
build --action_env PYTHON_BIN_PATH="/usr/bin/python3" build --action_env PYTHON_LIB_PATH="/usr/lib/python3/dist-packages" build --python_path="/usr/bin/python3" build:xla --define with_xla_support=true build --action_env TF_NEED_OPENCL_SYCL="0" build --action_env TF_NEED_ROCM="0" build --action_env TF_NEED_CUDA="1" build --action_env TF_NEED_TENSORRT="0" build --action_env CUDA_TOOLKIT_PATH="/usr/local/cuda" build --action_env TF_CUDA_COMPUTE_CAPABILITIES="3.0" build --action_env LD_LIBRARY_PATH="/usr/local/nvidia/lib:/usr/local/nvidia/lib64" build --action_env TF_CUDA_CLANG="0" build --action_env GCC_HOST_COMPILER_PATH="/usr/bin/gcc-4.8" build --config=cuda build:opt --copt=-march=native build:opt --copt=-Wno-sign-compare build:opt --host_copt=-march=native build:opt --define with_default_optimizations=true build:v2 --define=tf_api_version=2 test --flaky_test_attempts=3 test --test_size_filters=small,medium test --test_tag_filters=-benchmark-test,-no_oss,-oss_serial test --build_tag_filters=-benchmark-test,-no_oss test --test_tag_filters=-gpu test --build_tag_filters=-gpu build --action_env TF_CONFIGURE_IOS="0"
上記.tf_configure.bazelrcは、bazel build実行前に予め/tensorflow以下でconfigureコマンドを実行することで生成されるファイルです。
参考までに、以下にconfigureコマンド実行時のログを記載します。
% ./configure
Extracting Bazel installation...
WARNING: --batch mode is deprecated. Please instead explicitly shut down your Bazel server using the command "bazel shutdown".
You have bazel 0.24.1 installed.
Please specify the location of python. [Default is /usr/bin/python3]:
Found possible Python library paths:
/usr/lib/python3/dist-packages
/usr/local/lib/python3.6/dist-packages
Please input the desired Python library path to use. Default is [/usr/lib/python3/dist-packages]
Do you wish to build TensorFlow with XLA JIT support? [Y/n]: n
No XLA JIT support will be enabled for TensorFlow.
Do you wish to build TensorFlow with OpenCL SYCL support? [y/N]:
No OpenCL SYCL support will be enabled for TensorFlow.
Do you wish to build TensorFlow with ROCm support? [y/N]:
No ROCm support will be enabled for TensorFlow.
Do you wish to build TensorFlow with CUDA support? [y/N]: y
CUDA support will be enabled for TensorFlow.
Do you wish to build TensorFlow with TensorRT support? [y/N]:
No TensorRT support will be enabled for TensorFlow.
Found CUDA 10.0 in:
/usr/local/cuda/lib64
/usr/local/cuda/include
Found cuDNN 7 in:
/usr/lib/x86_64-linux-gnu
/usr/include
Please specify a list of comma-separated CUDA compute capabilities you want to build with.
You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus.
Please note that each additional compute capability significantly increases your build time and binary size, and that TensorFlow only supports compute capabilities >= 3.5 [Default is: 3.5,7.0]: 3.0
WARNING: XLA does not support CUDA compute capabilities lower than 3.5. Disable XLA when running on older GPUs.
Do you want to use clang as CUDA compiler? [y/N]:
nvcc will be used as CUDA compiler.
Please specify which gcc should be used by nvcc as the host compiler. [Default is /usr/bin/gcc]: /usr/bin/gcc-4.8
Do you wish to build TensorFlow with MPI support? [y/N]:
No MPI support will be enabled for TensorFlow.
Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native -Wno-sign-compare]:
Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]:
Not configuring the WORKSPACE for Android builds.
Preconfigured Bazel build configs. You can use any of the below by adding "--config=<>" to your build command. See .bazelrc for more details.
--config=mkl # Build with MKL support.
--config=monolithic # Config for mostly static monolithic build.
--config=gdr # Build with GDR support.
--config=verbs # Build with libverbs support.
--config=ngraph # Build with Intel nGraph support.
--config=numa # Build with NUMA support.
--config=dynamic_kernels # (Experimental) Build kernels into separate shared objects.
Preconfigured Bazel build configs to DISABLE default on features:
--config=noaws # Disable AWS S3 filesystem support.
--config=nogcp # Disable GCP support.
--config=nohdfs # Disable HDFS support.
--config=noignite # Disable Apache Ignite support.
--config=nokafka # Disable Apache Kafka support.
--config=nonccl # Disable NVIDIA NCCL support.
Configuration finished
今後、Tensorflowのバージョンが上がるなどして、上記設定では不足だったり、オプション指定の方法が変わることなどが考えられますが、そのような場合は改めてconfigureを実行して.tf_configure.bazelrcを生成し直すと良いでしょう。
Makefile
以下、Makefileの例です(GitHubからも取得できます)。
下記をコピーすると字下げされている箇所は複数スペースになると思いますが、MakefileではTabを使う必要がありますので、以下からコピーして使う場合は字下げ部分をTabに置き換えてください。
この作業が面倒な場合は、GitHubからの取得をお勧めします。
IMAGE=tak6uch1/tensorflow_jupyter
VERSION=latest
CONTAINER=tensorflow_jupyter
USER=user
build:
docker build -t $(IMAGE):$(VERSION) .
restart: stop rm run
uid=`id -u $(USER)`
ugrp=`id -g $(USER)`
run:
docker run \
--gpus '"device=0"' \
-itd \
-p 8888:8888 \
-v /etc/group:/etc/group:ro \
-v /etc/passwd:/etc/passwd:ro \
-v /home/user/work/cuda-tensorflow/work:/work \
-v /home/user/work/cuda-tensorflow/notebooks:/opt/notebooks \
-u $(uid):$(ugrp) \
--name $(CONTAINER) \
$(IMAGE)
run_root:
docker run \
--gpus '"device=0"' \
-itd \
-p 8888:8888 \
-v /home/user/work/cuda-tensorflow/notebooks:/opt/notebooks \
--name $(CONTAINER) \
$(IMAGE)
container=`docker ps -a | grep $(CONTAINER) | awk '{print $$1}'`
image=`docker images | grep $(IMAGE) | grep $(VERSION) | awk '{ print $$3 }'`
clean: rm
if [ "$(image)" != "" ] ; then \
docker rmi $(image); \
fi
rm:
if [ "$(container)" != "" ] ; then \
docker rm -f $(container); \
fi
stop:
if [ "$(container)" != "" ] ; then \
docker stop $(container); \
fi
exec:
docker exec -u $(uid):$(ugrp) -it $(CONTAINER) bash
exec_root:
docker exec -it $(CONTAINER) bash
logs:
docker logs $(CONTAINER)
USER=userはホストマシンのユーザ名に合わせてください。
/home/user/work/cuda-tensorflow/workなどのパスもお使いの環境に合わせて変更してください。
rootとして実行するとコンテナ内で作成したファイルがrootのファイルとなってユーザが編集できなくなり、取り回しが面倒になるため、-uでユーザとして実行しています。こちらのうまくいく方法2を取り入れ、/etc/passwdと/etc/groupをマウントする方法を採用しました。
Dockerイメージのビルドを行います。
$ make build
上記には数時間かかると思いますので、しばらく待ちます。
その後、以下のようにnvidia/cudaのイメージが表示されることを確認します。
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE tak6uch1/tensorflow_jupyter latest 9def828d8f5a 16 minutes ago 13.4GB
コンテナを起動します。
$ make run
コンテナに入ります。
$ make exec
まず、DockerからNVIDIAドライバが正常に見えているか確認します。Ubuntuホストマシンで実行した際と同様であれば問題ないです。
% nvidia-smi
Sun May 17 16:16:09 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.64.00 Driver Version: 440.64.00 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GT 650M On | 00000000:01:00.0 N/A | N/A |
| N/A 55C P0 N/A / N/A | 952MiB / 981MiB | N/A Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 Not Supported |
+-----------------------------------------------------------------------------+
続いてCUDAのコンパイラバージョンを確認します。
% nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2018 NVIDIA Corporation Built on Sat_Aug_25_21:08:01_CDT_2018 Cuda compilation tools, release 10.0, V10.0.130
cuDNNのバージョンを確認します。
% cat /usr/include/cudnn.h | grep CUDNN_MAJOR -A 2 #define CUDNN_MAJOR 7 #define CUDNN_MINOR 6 #define CUDNN_PATCHLEVEL 5 -- #define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL) #include "driver_types.h"
コンテナを停止するには以下を実行します。
$ make rm
動作確認
コンテナを起動して入り、各種動作確認を行います。
$ make run $ make exec
makeコマンドにより実行される内容については、上記Makefileを参照のこと。
C言語
まずはC言語プログラムの確認をします。
以下、おなじみのHello Worldプログラムをhello.cなどとして作成します(GitHubからも取得できます)。
次節のCUDAの例と対比するためにprintf呼び出し部分はhello()という関数にしてあります。
#include <stdio.h>
void hello(){
printf("Hello World!\n");
}
int main() {
hello();
return 0;
}
gccでコンパイルして以下のようにHello World!と表示されれば成功です。
% cd /work % gcc -o hello hello.c % ./hello Hello World!
CUDA
CUDA(Compute Unified Device Architecture)は、NVIDIA社のGPUコンピューティングプラットフォームの名称で、GPUを使った並列処理を簡単に実行できる環境のことです。
前節のC言語のHello WorldプログラムをGPUを使った並列処理として改造します。
並列実行した複数の処理が全く同じ文字列を表示しても面白くないので、通し番号付きでHello CUDA!と表示するようにしています。hello.cuなどとして作成します(GitHubからも取得できます)。
#include <stdio.h>
__global__ void hello(){
int i = blockIdx.x * blockDim.x + threadIdx.x;
printf("%d Hello CUDA!\n", i);
}
int main() {
hello<<< 2, 4 >>>();
cudaDeviceSynchronize();
return 0;
}
C言語プログラムとの違いは以下の点になります。
hello()関数の行頭に__global__が付いている
GPUで処理することを示すキーワードです。hello()関数内で宣言していない変数block〜、thread〜が使われている
並列実行された関数ごとに処理を分けるための数値で以下の意味です。- blockIdx.x ブロック番号
- blockDim.x ブロック数
- threadIdx.x スレッド番号
hello()関数呼び出し時に <<< ブロック数, スレッド数 >>> 記述がある
スレッドはCUDAにおける処理の最小単位で、スレッド数は1ブロックに属するスレッドの数を表し、ブロック数はそのスレッドの束をいくつ作るかを指定します。
結果、ブロック数×スレッド数の分だけ並列処理が実行されます。hello()関数実行後にcudaDeviceSynchronize()関数を呼び出している
GPUに投入した処理を待つ関数で、これを実行しないとGPU処理の結果を受け取らずにプログラムが終了してしまいます。
nvccでコンパイルして以下のように表示されれば成功です。なお、並列処理の実行順序は一意に決まらないため、番号順になりません。
% nvcc -o hello hello.cu % ./hello 4 Hello CUDA! 5 Hello CUDA! 6 Hello CUDA! 7 Hello CUDA! 0 Hello CUDA! 1 Hello CUDA! 2 Hello CUDA! 3 Hello CUDA!
Keras + cuDNN
cuDNN(CUDA Deep Neural Network library)は、CUDAでDeep Learningを高速に行うためのライブラリです。
GitHubから手書き文字認識MNISTのサンプルコードをダウンロードします。
% cd /work % git clone https://github.com/fchollet/keras.git
最近のTensorflowにはKerasが含まれていますが、サンプルコードはTensorflowにKerasが含まれていないときの記述になっているのでimport関連の記述を修正します。
% cp keras/examples/mnist_cnn.py . % vi mnist_cnn.py
修正した結果を以下に記載します(GitHubからも取得できます)。
'''Trains a simple convnet on the MNIST dataset.
Gets to 99.25% test accuracy after 12 epochs
(there is still a lot of margin for parameter tuning).
16 seconds per epoch on a GRID K520 GPU.
'''
from __future__ import print_function
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras import backend as K
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=tf.keras.losses.categorical_crossentropy,
optimizer=tf.keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
修正前との差分は以下です。
% diff mnist_cnn.py keras/examples/mnist_cnn.py 9,14c9,14 < import tensorflow as tf < from tensorflow.keras.datasets import mnist < from tensorflow.keras.models import Sequential < from tensorflow.keras.layers import Dense, Dropout, Flatten < from tensorflow.keras.layers import Conv2D, MaxPooling2D < from tensorflow.keras import backend as K --- > import keras > from keras.datasets import mnist > from keras.models import Sequential > from keras.layers import Dense, Dropout, Flatten > from keras.layers import Conv2D, MaxPooling2D > from keras import backend as K 44,45c44,45 < y_train = tf.keras.utils.to_categorical(y_train, num_classes) < y_test = tf.keras.utils.to_categorical(y_test, num_classes) --- > y_train = keras.utils.to_categorical(y_train, num_classes) > y_test = keras.utils.to_categorical(y_test, num_classes) 59,60c59,60 < model.compile(loss=tf.keras.losses.categorical_crossentropy, < optimizer=tf.keras.optimizers.Adadelta(), --- > model.compile(loss=keras.losses.categorical_crossentropy, > optimizer=keras.optimizers.Adadelta(),
ここで、GeForce GT 650M搭載のPCで上記コードを実行するとエラーになりました(GeForce GT 750M搭載のPCは問題なし)。
nvidia-smiを実行して確認すると、メモリの空き領域が少なかったためのようです。
% nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.64.00 Driver Version: 440.64.00 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GT 650M On | 00000000:01:00.0 N/A | N/A |
| N/A 43C P5 N/A / N/A | 675MiB / 981MiB | N/A Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 Not Supported |
+-----------------------------------------------------------------------------+
lsofでGPUを使用しているアプリを調べるとXorg, gnome-shell, chromeと表示されており、立ち上げていたChromeブラウザを閉じるとメモリの空き領域が増えてMNISTサンプルコードを実行することができました。
lsofはDockerコンテナからではなく、Ubuntuホスト側で実行します。
$ lsof /dev/nvidia*
MNISTサンプルコードを実行します。
このとき別のウィンドウでnvidia-smi -lとしておくことでGPUのメモリ使用量が変化し、GPUが使われていることを確認できます。
% time python mnist_cnn.py (((省略))) 2020-06-21 04:22:01.668506: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1640] Found device 0 with properties: name: GeForce GT 650M major: 3 minor: 0 memoryClockRate(GHz): 0.9 (((省略))) Test loss: 0.710387927532196 Test accuracy: 0.8402 real 7m32.738s user 5m30.087s sys 0m14.930s
GeForce GT 750M搭載のPCでは以下でした。
Test loss: 0.7078132617950439 Test accuracy: 0.8423 real 7m4.329s user 4m57.915s sys 0m7.722s
次に環境変数CUDA_VISIBLE_DEVICESに-1を設定することでGPUを無効にした場合を試します。
% export CUDA_VISIBLE_DEVICES=-1 % time python mnist_cnn.py (((省略))) 2020-06-21 06:12:31.350070: E tensorflow/stream_executor/cuda/cuda_driver.cc:318] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected (((省略))) Test loss: 0.8166104441642761 Test accuracy: 0.8348 real 14m31.986s user 100m23.765s sys 1m51.786s
GeForce GT 750M搭載のPCでは以下でした。
Test loss: 0.7812927163124085 Test accuracy: 0.8332 real 9m28.581s user 63m39.594s sys 1m31.441s
user timeはCPUが稼働した時間を表し、前回のGPU使用時より大きくなっていることがわかります。GPU有効時は、GPUに処理を投げてCPUとしては待機(このときuser timeは進行しない)していたのが、GPUを無効にしたことによりCPUで演算しているためと考えられます。
上記の例では実時間(real time)で比較して、GPU使用により約2/3〜1/2程度に短縮できたことがわかります。
Jupyter Notebook
Dockerで画像を扱うにはSSHやVNC等の方法がありますが、Jupyter Notebookを使うことも
$ make logs
上記で出たログのうち、http://127.0.0.1:8888/?token=〜の部分をCtrl+クリック、またはコピーしてブラウザの検索窓に貼り付けます。以下のようにJupyter Notebookが立ち上がれば成功です。
ただし、GeForce GT 650M搭載のPCでは、前述と同様にChromeを立ち上げるとGPUのメモリを消費してしまい、MNISTがうまく流れなくなってしまいました(GeForce GT 750M搭載のPCでは問題なし)。
Firefoxも試しましたが、Chromeよりはメモリ使用量が少ないものの同様にエラー終了となりました。
代替手段として、Ubuntuホストマシンの8888ポートを開放し、LAN上の別のマシンからJupyter Notebookに接続することで回避しましたので、その方法を説明します。
以下、Dockerコンテナ内の操作ではなく、Ubuntuホストマシンの操作になります。
まず、ufwコマンドを使ってポートを開けます。
$ sudo ufw enable $ sudo ufw allow 8888 $ sudo ufw status Status: active To Action From -- ------ ---- 8888 ALLOW Anywhere 8888 (v6) ALLOW Anywhere (v6)
次にUbuntuホストマシンのIPアドレスを調べます。
ifconfigが既にある場合は1行目のnet-toolsのインストールは不要です。
$ sudo apt install net-tools
$ ifconfig
((( 省略 )))
wlp4s0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.179.16 netmask 255.255.255.0 broadcast 192.168.179.255
((( 省略 )))
上記は無線LAN接続時の例で、ifconfigでお使いのネットワークのIPアドレスを調べます。inetに続く値がIPアドレスで、私の場合192.168.179.16でした。
ここまでできたら、次は別のPCでChrome等のブラウザを立ち上げ、上記make logsで調べたURLの127.0.0.1の部分を先程調べたUbuntuホストマシンのIPアドレス192.168.179.16に置き換えたURLを入力します。
別PCのためコピペができず、画面を見ながら手入力しました。クラウド経由のコピペやファイル渡しなどを利用しても良いでしょう。
以下のように表示できたら、New→Python3と選択してPython3の入力画面を立ち上げます。

以下のコマンドを入力し、Shift+Enterを押します。(%%timeのあとは普通にEnterで改行、〜.pyのあとはShift+Enter)
%%time run -i /work/mnist_cnn.py
正常に実行できると、Dockerコンテナから実行したのと同様のログが表示されます。

最近のMacとの比較
ここまでで、古いMacでGPUを使用した機械学習環境を立ち上げ、GPUの効果も確認できた訳ですが、最近のMac(NVIDIA GPU無し)と比べるとどうなのかが気になり、以下のスペックのMacで同じmnist_cnn.pyを実行してみました。
| Item | Spec. |
|---|---|
| Machine | MacBook Pro 15-inch 2019 |
| CPU | 8-Core Intel Core i9 9880H 2.3GHz |
Tensorflow環境はUbuntuではなく、こちらのDocker for Mac上に構築したDebianを使いました。
以下のとおり、GPU使用の古いMacより少し速いという結果でした。
Test loss: 0.810593843460083 Test accuracy: 0.8277999758720398 real 6m40.575s user 72m23.416s sys 1m32.977s
やはり、底辺レベルのGPU環境のためと思いますが、前向きに捉えるならば、GPUを使えば新しいNVIDIA GPU非搭載PCと同等の性能が出せてコスパが良いと言うこともできそうです。
他の機械学習環境との比較
無料でGPUを利用できるクラウドベースのGoogle Colabの環境立ち上げについてはこの記事に書いています。
結果は以下のとおりで、圧倒的にGoogle Colabが速いです!
Test loss: 0.767807126045227 Test accuracy: 0.8345999717712402 CPU times: user 33.2 s, sys: 7.68 s, total: 40.9 s Wall time: 53.1 s
また、機械学習の入門機とも呼べるJetson-Nanoの環境立ち上げはこの記事に書きました。
Jetson-Nanoよりは本記事で紹介したNVIDIA GPU搭載Macのほうが高速でした。
それぞれの実行速度の比較については以下の記事をご覧ください。
機械学習環境ベンチマーク
まとめ
NVIDIA GPU搭載のMacをUbuntu Linuxのデュアルブートにして、機械学習環境を立ち上げる方法について説明しました。
苦労して立ち上げたGPU環境ではありますが、新しいPCやGoogle Colabには及ばないという結果でした。
しかしながら、自分でTensorflowをソースコードからビルドしたのは良い経験になりました。
GPU、ドライバ、各種ツール、ライブラリのバージョンには依存関係があり、一部を間違うと正常に動かなくなるので、先人たちによる実績のあるバージョン情報が役に立ちました。
Google Colabには全くかなわなかったGPUマシンの使い道についてですが、ローカルで試す場合や長時間かかるJOBに対してGoogle Colabの制限を回避するのが面倒な場合などに昼夜流しておく、もしくは複数案件を学習させる際の第2の手段など、活用の場面はあるのではないかと思います。
NVIDIA GPU搭載のMacは中古でも6〜8万程度はすると思います。(2020/11月現在)
低予算で機械学習を始めるなら断然Jetson-Nanoがオススメです。

本記事で紹介した内容に比べるとはるかに環境構築は楽で、DeepStreamなど動画のデモもすぐに体験できます。
トラブルシューティング
外部モニターの問題
NVIDIAドライバをインストール後、HDMI端子につないでいた外付けモニターは認識するものの黒いままでマルチウィンドウが使えなくなりました。
使用したMacBook Proには2つのThunderbolt端子と1つのHDMI端子があり、モニター出力としては計3つの端子が使えるのですが、NVIDIAドライバインストール後はThunderbolt端子のうち1つ(手前側)のみ画面表示(マルチウィンドウ)できました。
HDMI端子を有効にする方法がわからず、画面表示できたThunderbolt端子を使うことにしました。
Docker実行時のエラー
nvidia-container-toolkitをインストールしないままdocker run --gpusを実行すると以下のエラーが出て実行できないので、インストールしてから実行し直すと良いです。
$ docker run --gpus all nvidia/cuda:10.0-cudnn7-devel-ubuntu18.04 nvidia-smi docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]]. ERRO[0000] error waiting for container: context canceled
Tensorflowをpipインストールしたときのエラー
当初、pipでTensorflowをインストールしようとしたのですが、対応しているのはcompute capability 3.5以上ということでエラー終了しました。
2020-05-18 15:07:13.801635: I tensorflow/compiler/xla/service/platform_util.cc:197] StreamExecutor cuda device (0) is of insufficient compute capability: 3.5 required, device is 3.0 2020-05-18 15:07:13.801799: F tensorflow/stream_executor/lib/statusor.cc:34] Attempting to fetch value instead of handling error Internal: no supported devices found for platform CUDA Aborted (core dumped)
Tensorflow公式ページによるとcompute capability 3.0の場合はソースからのビルドへと案内されるので、pipからインストールはせずに、ソースからビルドしました。
なお、Tensorflowのconfigureのログには、以下のように3.5以上に対応とのメッセージが出て不安になりながらも進めましたが、どうやら無事GPUを使えているようです。
TensorFlow only supports compute capabilities >= 3.5
TensorflowでOUT OF MEMORYエラー
gccのバージョンがUbuntu 18.04のデフォルト7.4だった際に出たエラーです。
2020-05-19 15:43:06.776079: E tensorflow/stream_executor/cuda/cuda_driver.cc:828] failed to allocate 52.12M (54657024 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY: out of memory
Dockerfileでapt install gcc-4.8 g++-4.8とすることで解消しました。
Bazelの出力先に関するWarning
Windowsマシンがデフォルトで想定されていて、以下のようなWarningが出ました。
DEBUG: /tmp/external/bazel_tools/tools/cpp/lib_cc_configure.bzl:115:5:
Auto-Configuration Warning: 'TMP' environment variable is not set, using 'C:\Windows\Temp' as default
以下のようにDockerfile中のbazel buildの前に環境変数TMPを定義することで回避できました。
ENV TMP=/tmp
Python3のみインストール時のBazelのエラー
Tensorflow公式ページではPython 2.7が標準のフローとして説明されていますが、私の場合、Python3しか使わないため、Python3のみインストールしました。
そうすると、Tensorflowのインストール中に/usr/bin/pythonが使われる箇所があるようで、以下のようなエラーが出ました。
[0 / 9] [-----] Expanding template tensorflow/tools/compatibility/tf_upgrade_v2 ... (2 actions, 0 running) ERROR: /root/.cache/bazel/_bazel_root/68a62076e91007a7908bc42a32e4cff9/external/pcre/BUILD.bazel:5:1: C++ compilation of rule '@pcre//:pcre' failed (Exit 127) /usr/bin/env: 'python': No such file or directory Target //tensorflow/tools/pip_package:build_pip_package failed to build
Dockerfile中でpythonにシンボリックリンクすることで解決しました。
RUN ln -s /usr/bin/python3 /usr/bin/python
Bazel build時にno known conversionエラー
bazel buildで以下のエラーが出ました。こちらのページによるとnumpy 1.19.0で後方互換のない更新が入ったとのことで、pip3 install 'numpy<1.19.0'として解決しました(Dockerfileに反映済み)。
tensorflow/python/lib/core/bfloat16.cc:608:60: note: no known conversion for argument 2 from '<unresolved overloaded function type>' to 'PyUFuncGenericFunction {aka void (*)(char**, const long int*, const long int*, void*)}'
Target //tensorflow/tools/pip_package:build_pip_package failed to build
INFO: Elapsed time: 562.223s, Critical Path: 147.97s
INFO: 692 processes: 692 local.
FAILED: Build did NOT complete successfully
NVIDIA GPUをセカンダリに
メインディスプレイ(MacBookの画面)表示にもNVIDIA GPUが使われて、GT 650Mには1GBしかないGPUのメモリリソースのうち400MB近くgnome-shellが使っていたので、2つ搭載されているGPUのうちのもう1つIntel GPUをプライマリにすることを試みたのですが、画面表示がうまくできなくなってしまいました。
画面表示がうまくいかないだけならGUI無しのターミナルのみで操作できるかと思ったのですが、NVIDIAドライバが正常に動かなくなり、nvidia-smiなどもできなくなったので、これは諦めました。
$ prime-select query nvidia $ sudo prime-select intel $ prime-select query intel $ sudo reboot
この後、黒画面で何とかコマンドは受け付ける状態にはなったものの、表示が崩れて使いものにならない(表示されている文字を想像して入力する必要がある)のと、nvidia-smiも動かなくなってしまいました。
/etc/default/grubをいじってみたりしたのですが、解決に至っていません。
GPUメモリ不足
GPUのメモリ不足の際に以下のエラーが出てMNISTが流れない問題が発生しました。
Chromeを閉じてから再実行することで回避しました。
ResourceExhaustedErrorTraceback (most recent call last)
書籍紹介
Pythonや画像処理、機械学習関連のおすすめ書籍を紹介します。

実践して楽しむことを重視していて、充実のサンプルコードで画像認識やテキスト分析、GAN生成といったAI応用をGoogle Colab環境下で体験できます。

基礎から応用までわかりやすい説明でコード例も多数載っていて、初学者の入門書としては必要十分と感じています。
さらにPythonらしいコードの書き方も言及されていて、スマートなコードが書けるようになります。
詳解 OpenCV 3 ―コンピュータビジョンライブラリを使った画像処理・認識

最新のOpenCV4には対応していないのですが、やはりオライリー、基礎を学ぶには十分な情報があり、この本から入ることをおすすめします。
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装

この本は、機械学習の仕組みを学ぶのにとても良い本だと思います。
Tensorflow/Kerasなどの既存プラットフォームを使うのではなく、基本的な仕組みを丁寧に説明し、かんたんなPythonコードで実装していく手順を紹介してくれます。
機械学習のコードがどのような処理をしているのか、想像できるようになります。
参考文献
- macOS 10.15.1 CatalinaではNVIDIA GPU搭載のMacでCatalina初期リリース時にサポートされていなかったSceneKitによる描写が可能に。(https://applech2.com/archives/20191102-macos-10-15-1-catalina-support-scenekit.html)
- macOS MojaveとUbuntu 18.04をデュアルブート(新しいMac等は非対応)(https://qiita.com/Yasu31/items/b24efc9986899f5aabbf)
- 【最新情報】NVIDIAのドライバーがmacOS Mojave & Catalinaで使えない問題について(https://bombox.net/mac/nvidia-driver-issue-between-apple/)
- NVIDIA Docker って今どうなってるの? (19.11版)(https://qiita.com/ksasaki/items/b20a785e1a0f610efa08)
- Ubuntu 18.04へのCUDAインストール方法(https://qiita.com/yukoba/items/4733e8602fa4acabcc35)
- dockerでGPUディープラーニング(TensorFlow+Keras)を構築した(https://note.com/funmylife/n/n0cbe3888c05f)
- dockerでvolumeをマウントしたときのファイルのowner問題(https://qiita.com/yohm/items/047b2e68d008ebb0f001)
- Tensorflow公式(https://www.tensorflow.org/install/source?hl=ja)
- Bazel公式(https://docs.bazel.build/versions/master/install-ubuntu.html)
- GPUディープラーニング環境(CUDA+cuDNN+TensorFlow+Keras)を構築した(https://note.com/funmylife/n/na35c2dd858ae)